本文涉及的四项技术并不是孤立的优化点——它们沿着同一条主线演进:先缓存 K/V(KV Cache)→ 管好内存(vLLM)→ 压缩 K/V 体积(TurboQuant)→ 让 Attention 计算本身更快(FlashAttention)。 前三项都是在处理推理时的 KV Cache 这一核心数据结构,最后一项优化的是 Attention 计算本身。四者可以同时使用。
为什么需要 KV Cache?
自回归生成时,每生成一个 token,都要对整个已有序列做一次完整的 Attention 计算。没有 KV Cache 时,生成第 $t$ 个 token 的复杂度是 $O(t^2)$,1000 token 的序列要做 100 万次乘法,而且大量计算是重复的。
生成「我爱北京天安门」分两个阶段:
- Prefill(预填充):把 prompt(如「我爱北」)一次性并行过完所有 $L$ 层。每一层,所有 token 的隐状态都会互相做 Attention、融合信息、被更新。每层计算完,把该层所有 token 的 K/V 存进 KV Cache。
- Decode(解码):每次只生成 1 个新 token(如「京」),它从第 1 层走到第 $L$ 层。「我/爱/北」不再重新计算,它们每一层的 K/V 都已经在 Prefill 时存好了。
以 3 层 Transformer 为例,Prefill 时「我/爱/北」三个 token 并行通过每一层:
Prefill 结束后,「我/爱/北」每一层的 K/V 都存好了。它们的隐状态已经在每一层被充分更新融合,任务完成,不会再参与后续 Decode 的前向计算。
现在生成「京」,它从 Layer 1 开始,逐层向上:
「我/爱/北」在 Decode 阶段完全不动——它们只是以 K/V 向量的形式静静地躺在缓存里,供「京」在每一层来查询。
用简化例子说明:维度 $d_h = 4$,已生成「我 爱 北」3 个 token,现在生成第 4 个 token「京」。
第 1 步:KV Cache 里已经存好了前 3 个 token 的向量
第 2 步:计算新 token「京」自己的 Q、K、V 向量
第 3 步:将 K_京、V_京 追加到 KV Cache(扩展为 4×4)
第 4 步:Q_京 和 K_full(4 行)做点积,得到 4 个 Attention Scores
第 5 步:softmax 归一化,得到 4 个注意力权重
第 6 步:用 4 个权重对 V_full 加权求和,得到「京」的输出向量
关键点总结:
① 「京」必须也用自己的 K_京、V_京 参与计算(Causal Attention 可以 attend to 自身)
② K_京、V_京 先追加到 KV Cache,再用完整的 4 行做 Attention
③ 本轮只计算了「京」的 Q/K/V 各 1 次投影,前 3 个 token 的 K/V 全部来自缓存,节省了 6 次投影运算
④ 计算完成后,KV Cache 从 3 行扩展为 4 行,供下一个 token(「天」)使用
本质上,KV Cache 是一个用内存换时间的策略:把之前算过的 K、V 矩阵存下来,避免重复计算。
Query 代表「当前 token 想问什么」,每生成一个新 token,Q 是全新的(这个 token 自己的投影),所以 Q 不需要缓存。K 和 V 代表「已有 token 提供的键和值」,之前 token 的 K、V 不会变,所以可以缓存。
不会。推理阶段(inference)是纯前向传播,没有反向传播,模型所有参数($W_K$、$W_V$ 等权重矩阵)都是固定不变的。KV Cache 里存的是已有 token 经过固定权重算出的向量,「京」的 Attention 计算只会读取这些缓存值,绝不会修改它们。
参数更新只发生在训练阶段(有 loss、有 backward),推理时模型是只读的。KV Cache 本质上是一个只会追加写入(append)新 token 向量的缓冲区,不会对已有行做任何改动。
这是个很容易混淆的问题。核心区别是:训练时根本没有"逐个生成 token"这回事——用的是 Teacher Forcing,整个序列一次性并行算完所有位置的预测。
Teacher Forcing(教师强制):训练时把完整的目标序列一次性喂进去,加上 Causal Mask(下三角掩码)让每个位置只能看自己之前的 token,然后一次前向传播就同时算出所有位置的预测 logits 和 loss:
| 对比维度 | 推理(Inference) | 训练(Training) |
|---|---|---|
| 生成方式 | 真正自回归,逐 token 生成 | Teacher Forcing,并行计算所有位置 |
| 每步的输入 | 模型自己生成的上一个 token | 永远是 ground truth token(即使上步预测错了) |
| 参数状态 | 固定只读 | 每个 step 都会被更新 |
| KV Cache | ✅ 有效:避免重复投影,节省算力 | ❌ 无效:全并行无重复;且参数更新后缓存立刻失效 |
| 内存优化技术 | KV Cache、PagedAttention | FlashAttention(减少 attention 矩阵的 HBM IO)、梯度检查点 |
在 PPO 等强化学习微调中,Policy Model 需要真正自回归地采样一段回答,这里确实会用 KV Cache 加速。但这部分本质上是对 Policy Model 的推理,不是普通的监督训练 forward。
用 NumPy 实现单层单头的简化 Transformer,分别跑 无 KV Cache 和 有 KV Cache 两个版本,对比 K/V 投影次数。两者输出完全相同,KV Cache 是无损优化。
import numpy as np
np.random.seed(42)
d_model = 8 # embedding 维度(单头,d_h == d_model)
# 固定权重矩阵(推理时只读,不会更新)
W_Q = np.random.randn(d_model, d_model) * 0.3
W_K = np.random.randn(d_model, d_model) * 0.3
W_V = np.random.randn(d_model, d_model) * 0.3
# 模拟 5 个 token 的 embedding:「我爱北京天」
tokens = ["我", "爱", "北", "京", "天"]
embeddings = np.random.randn(len(tokens), d_model) * 0.5
def softmax(x):
e = np.exp(x - x.max())
return e / e.sum()
def attention(q, K_mat, V_mat):
"""单个 query 对整个 K/V 做 scaled dot-product attention"""
scores = K_mat @ q / np.sqrt(d_model) # (seq_len,)
weights = softmax(scores) # (seq_len,)
return weights @ V_mat # (d_model,)
# ─────────────────────────────────────────────────────────
# 版本 A:无 KV Cache —— 每次生成都重新计算所有历史 token 的 K/V
# ─────────────────────────────────────────────────────────
print("=" * 60)
print("版本 A:无 KV Cache")
print("=" * 60)
total_proj_no_cache = 0
for i, token in enumerate(tokens):
# 每次都对当前 token 及之前所有 token 重新做 K/V 投影
context = embeddings[:i+1] # (i+1, d_model)
K_all = context @ W_K # 重新算!(i+1, d_model)
V_all = context @ W_V # 重新算!(i+1, d_model)
total_proj_no_cache += 2 * (i + 1) # K+V 各 1 次,共 2*(i+1) 次
q = embeddings[i] @ W_Q
out = attention(q, K_all, V_all)
print(f" 生成「{token}」: 重新算了 {2*(i+1):2d} 次 K/V 投影 "
f"out[0]={out[0]:.4f}")
print(f"\n ✗ 总 K/V 投影次数:{total_proj_no_cache}\n")
# ─────────────────────────────────────────────────────────
# 版本 B:有 KV Cache —— 只算新 token 的 K/V,历史的直接复用
# ─────────────────────────────────────────────────────────
print("=" * 60)
print("版本 B:有 KV Cache")
print("=" * 60)
cache_K = [] # 每步 append 新 token 的 K 向量
cache_V = [] # 每步 append 新 token 的 V 向量
total_proj_cache = 0
for i, token in enumerate(tokens):
# 只计算当前新 token 的 K、V(1 次投影,不管历史多长)
k_new = embeddings[i] @ W_K # 只算自己的!
v_new = embeddings[i] @ W_V # 只算自己的!
total_proj_cache += 2 # 永远只有 2 次
cache_K.append(k_new) # 追加进缓存
cache_V.append(v_new)
K_all = np.stack(cache_K) # 从缓存读,无需重算
V_all = np.stack(cache_V)
q = embeddings[i] @ W_Q
out = attention(q, K_all, V_all)
print(f" 生成「{token}」: 只算了 2 次 K/V 投影 "
f"out[0]={out[0]:.4f} (cache 中 {len(cache_K)} 个 token)")
print(f"\n ✓ 总 K/V 投影次数:{total_proj_cache}\n")
# ─────────────────────────────────────────────────────────
# 对比总结
# ─────────────────────────────────────────────────────────
print("=" * 60)
saving = total_proj_no_cache - total_proj_cache
pct = saving / total_proj_no_cache * 100
print(f" 无 KV Cache:{total_proj_no_cache} 次投影")
print(f" 有 KV Cache:{total_proj_cache} 次投影")
print(f" 节省:{saving} 次({pct:.0f}%)")
print(f" 结论:两个版本 out[0] 完全相同 → KV Cache 是无损优化")
print("=" * 60)
# 预期输出:
# 版本 A 总投影次数:2+4+6+8+10 = 30
# 版本 B 总投影次数:2×5 = 10
# 节省 20 次(67%);序列 100 token 时节省 ~99%
复制到本地,pip install numpy 后直接 python kv_cache_demo.py 即可运行,亲眼验证节省次数和输出一致性。
KV Cache 的内存开销
KV Cache 是推理内存压力的主要来源之一。计算公式:
- $2$:K 和 V 各一份
- $L$:Transformer 层数
- $H$:注意力头数(Multi-Head Attention 中的 head 数)
- $d_h$:每个头的维度(= 总维度 $d_{model}$ / 头数 $H$)
- $T$:序列长度(已生成 + 输入 token 总数)
- bytes:每个数值的字节数(fp16 = 2 bytes,int8 = 1 byte)
LLaMA-2 7B 的参数:$L=32$ 层,$H=32$ 头,$d_{model}=4096$,所以 $d_h = 4096 / 32 = 128$。
假设序列长度 $T=4096$,使用 fp16(每个数值 2 bytes):
| 维度 | 数值 | 含义 |
|---|---|---|
| K/V 两份 | × 2 | 每层既要存 K 矩阵,也要存 V 矩阵 |
| 层数 $L$ | × 32 | 32 个 Transformer 层,每层独立存 |
| 头数 $H$ | × 32 | Multi-Head Attention 有 32 个头 |
| 每头维度 $d_h$ | × 128 | 每个头的 K/V 向量长度 = 4096 ÷ 32 |
| 序列长度 $T$ | × 4096 | 已经处理的 token 数(prompt + 已生成) |
| fp16 精度 | × 2 bytes | fp16 每个数值占 2 字节 |
相当于模型权重(约 13 GB)的 15%。如果 batch size = 8(同时处理 8 个请求),就是 16 GB,几乎等于一张 A100(80 GB)的 20%。
如果上下文扩展到 128K token(128 × 4096):KV Cache = 2 GB × 32 = 64 GB,一张 A100 只够存 1 条请求的 KV Cache,根本没有空间放模型权重。这就是为什么长序列推理是瓶颈。
KV Cache 引发的问题
内存碎片化
不同请求的序列长度不同,如果静态分配 max_len 大小的 KV Cache,短序列浪费大量空间。PagedAttention(vLLM)用分页管理解决这个问题。
带宽瓶颈
每次生成 token 需要把整个 KV Cache 从显存读一遍(内存带宽受限),而不是算力受限。这是为什么 GPU 利用率低但生成慢的原因。
Batch 受限
KV Cache 占用显存随 batch size 线性增长,导致 serving 时不能开大 batch,吞吐量受限。
变体:MQA / GQA——减少 KV Cache 大小
原始的 Multi-Head Attention(MHA)中,每个头都有独立的 K、V 投影矩阵。KV Cache 大小正比于头数 $H$。两种变体通过让多个 Q 头共享 K、V 头来压缩 KV Cache:
| 方案 | K、V 头数 | KV Cache 压缩比 | 代表模型 | 效果损失 |
|---|---|---|---|---|
| MHA(标准) | = Q 头数(如 32) | 1×(基准) | GPT-3、LLaMA-1 | 基准 |
| MQA(Multi-Query) | 只有 1 个 K/V 头 | H×(如 32×) | PaLM、Falcon | 明显(1 个 KV 头信息瓶颈) |
| GQA(Grouped-Query) | G 个 K/V 头(G < H) | H/G×(如 8×) | LLaMA-2 70B、Mistral | 极小(通常 <1% 差距) |
假设 $H=32$ 个 Q 头,GQA 设 $G=8$ 个 K/V 头。每 4 个 Q 头共享 1 对 K/V:
Q head 0,1,2,3 → 共享 KV head 0 Q head 4,5,6,7 → 共享 KV head 1 ... Q head 28,29,30,31 → 共享 KV head 7
KV Cache 从 $32 \times d_h$ 降为 $8 \times d_h$,缩小 4 倍。每个 Q 头在 Attention 时,用自己的 Q 和对应组的 K/V 做计算,公式不变,只是 K/V 被多个 Q 头复用。
LLaMA-2 70B 用了 GQA(64 个 Q 头,8 个 KV 头),KV Cache 压缩 8×,是 70B 模型能在单机 8×A100 上跑起来的关键之一。
MQA 只有 1 个 KV 头,32 个 Q 头都在问同一个 K/V,等于把所有头的「值得关注的信息」压缩到一个向量里,信息瓶颈严重。GQA 每组 4 个头共享一个 KV,每组 KV 可以专注一类信息(如语法、语义、位置),信息瓶颈小得多。
来源:"Efficient Memory Management for Large Language Model Serving with PagedAttention",Woosuk Kwon et al.,UC Berkeley & Stanford,SOSP '23(arXiv:2309.06180)。
v = Virtual(虚拟)。整个系统的核心机制就是把操作系统的「虚拟内存」思想搬到 LLM 的 KV Cache 管理上:给每条请求一个连续的「逻辑视图」,背后映射到 GPU 显存里分散的物理块——和 OS 让每个进程以为自己独占连续内存是完全相同的抽象。所以叫 Virtual LLM(vLLM)。
KV Cache 解决了「重复计算」的问题,但当多个请求同时在线推理(Batched Serving)时,内存碎片化成为新的瓶颈——现有系统有效利用率只有 20%–38%,其余都是碎片浪费。PagedAttention 借鉴操作系统的虚拟内存分页机制,把 KV Cache 切成固定大小的 Block,用 Block Table 做逻辑→物理地址映射,将内存利用率提升到 96%,吞吐量提升 2–4×。
传统 KV Cache 的内存浪费
用停车场类比更好理解:
🅿️ 内部碎片(Internal Fragmentation):你预订了连续 16 个停车位(因为不知道最多要停几辆),实际只停了 4 辆,剩下 12 个位子空着——但这 12 个位子是你的,别人根本没法用。请求结束后才发现白白占了这么多空间,纯浪费。
🅿️ 外部碎片(External Fragmentation):停车场已经分配了 A区(16位)和 B区(16位),中间夹了一个不规则的小缝隙(比如 3 个位子),这个缝隙太小、不连续,新来的车要 4 个连续车位,缝进去分配不了。不是因为没空间,而是剩余空间全是零碎的洞,凑不成一整块连续的。
关键区别:内部碎片是「分配了但没用完」,外部碎片是「没分配但零散凑不起来」。
现有 LLM 服务系统(如 FasterTransformer、Orca)把每个请求的 KV Cache 存成一块连续内存,且由于不知道这条请求最终会生成多少 token,只能按最大序列长度(max_len)一次性预分配。这就同时引入了两种浪费:
旧系统一开始就给每条请求预留连续的 16 格(因为不知道会生成多少 token):
A 区(16格)+ B 区(16格)之间,内存分配器(buddy allocator)可能产生一些零散空洞。新来的请求 C 需要连续 16 格,但空洞全是碎片,拼不出完整的一块——哪怕剩余总量够,也没法分配。这就是外部碎片。
小结:内部碎片 = 分配了 16 格只用了 6 格(块内浪费);外部碎片 = 两块之间的零散空洞(块外浪费)。两种浪费叠加,导致旧系统 GPU 显存有效利用率只有 20%–38%。
- Orca (Max):仅 20.4% 用于真实 KV,79.6% 是碎片/预留 → 能同时处理的请求数极少
- Orca (Pow2):38.2% 有效(按 2 的幂次分配,稍好一些)
- vLLM:96.3% 有效,近乎零浪费,批量大小(batch size)可大幅提升,吞吐量 2–4×
PagedAttention 怎么解决这个问题?
PagedAttention 的核心思想:不再按最大长度预分配连续内存,改为按需分配固定大小的 Block。每个 Block 只存 B 个 token 的 KV(论文用 Block Size = 16,下面例子用 4 方便看)。用完一个 Block 再申请下一个,Block 之间不需要物理相邻。
回忆旧系统:请求 A、B 各预占 16 格,总共占了 32 格,但实际只用了 11 格,利用率 34%。
看看 vLLM 怎么做:用一个就申请一个 Block(4 格),用完再要下一个。
类比你手机里的通讯录:你记的是「妈妈」「老王」这些名字(逻辑地址),手机背后实际存的是 138xxxx、139xxxx 这些号码(物理地址)。换手机时号码可能变,但你在通讯录里找「妈妈」还是能打通——这个「名字→号码」的对应关系,就是映射表。
vLLM 里:
- 逻辑 Block(L0、L1、L2…):请求自己视角里的「第几块内存」,L0 就是第 1 块、L1 是第 2 块……从 0 开始顺序编号。请求感知到的是连续的,它不知道也不关心背后的物理位置。
- 物理 Block(P0、P3、P7…):GPU 显存里真实的内存块编号,可以散落在显存任何位置,不需要相邻。
- Block Table:每条请求独有的一张小映射表,记录「L0 → P几」「L1 → P几」……就像通讯录一样。CUDA kernel 计算 Attention 时,拿着这张表按 L0→L1→L2 的顺序查出对应物理 Block,逐块取 KV 来计算。
| 逻辑 Block | 物理 Block | 内容 |
|---|---|---|
| L0 | P0 | Four / score / and / seven |
| L1 | P1 | fathers / brought / ░ / ░ |
| 逻辑 Block | 物理 Block | 内容 |
|---|---|---|
| L0 | P2 | You / only / live / once |
| L1 | P3 | !/ ░ / ░ / ░ |
① 旧系统一开始就分配 max_len=16 格;vLLM 只有 Prefill 时用了几格就申请几格(按 Block 粒度)
② 旧系统要求整块连续;vLLM 的 P0、P1、P2、P3 可以散落在 GPU 显存任何位置(通过 Block Table 映射),不需要相邻
③ 请求 B 完成后,vLLM 立刻把 P2、P3 还给空闲池,新请求 D 可以复用这两个物理 Block
Block Table 与 Decode 过程
vLLM 为每条请求维护一个 Block Table,记录「逻辑 Block 编号 → 物理 Block 地址」的映射。下面用格子图逐步演示整个 Decode 过程:
① Prefill 阶段:Prompt「Four score and seven years ago our」(7 token)
| 逻辑 Block | 物理 Block | 已填/4 |
|---|---|---|
| L0 | P7 | 4/4 ✓满 |
| L1 | P1 | 3/4 ░1空 |
② 第 1 步 Decode:生成「fathers」,填入 P1 的第 4 个 slot
| 逻辑 | 物理 | 已填/4 |
|---|---|---|
| L0 | P7 | 4/4 ✓满 |
| L1 | P1 | 4/4 ✓满 |
③ 第 2 步 Decode:生成「brought」,P1 已满,vLLM 新分配 P3
| 逻辑 | 物理 | 已填/4 |
|---|---|---|
| L0 | P7 | 4/4 ✓满 |
| L1 | P1 | 4/4 ✓满 |
| L2 | P3 ← 新分配 | 1/4 |
💡 关键直觉:Attention 计算时,CUDA kernel 拿着 Block Table 顺序读取 L0→P7、L1→P1、L2→P3,把三块物理上不相邻的 Block 拼成一个逻辑上连续的 KV 序列做计算——就像 CPU 的页表查询一样透明。
KV Cache 共享机制(为什么多个请求能共享同一个 Block?)
有三种很常见的情况:
① Parallel Sampling(并行采样):用户问「写 3 个版本的广告语」,服务端对同一个 prompt 一次性生成 3 条输出。这 3 条输出的 prompt 部分完全相同。
② Beam Search(束搜索):生成时保留 k 条最优路径,这 k 条路径在大多数时候有相同的前缀 token。
③ System Prompt 共享:所有用户请求都带同一段「你是一个有帮助的助手…」系统提示,这段文字每次都要 Prefill,但 KV 结果完全相同。
关键洞察:如果两个序列的前缀 token 完全相同,它们算出来的 K/V 向量也完全相同——没必要存两份,让 Block Table 里两行都指向同一个物理 Block 就行了!
用户发来:「请用一句话介绍 KV Cache」,服务端要生成 3 条不同回答(Sampling × 3)。
Block Size = 4,prompt 是 8 个 token,需要 2 个 Block。
| 序列 | 逻辑 L0 | 逻辑 L1 | 逻辑 L2(自己的生成) |
|---|---|---|---|
| 序列 A | P0 ←共享 | P1 ←共享 | P2(独有) |
| 序列 B | P0 ←共享 | P1 ←共享 | P3(独有) |
| 序列 C | P0 ←共享 | P1 ←共享 | P4(独有) |
vLLM:只需 2 个 Block(P0+P1),三条序列都指向同一份,节省了 4 个 Block
P0、P1 上有一个引用计数 ref_count = 3,只要还有任何序列在用,这两个 Block 就不会被释放。
这就是 Copy-on-Write(写时复制),和 Linux fork() 的原理完全一样:
平时:共享,谁也不复制,读的时候直接读 P0、P1。
写的时候:「等等,这个 Block 还有别人在用(ref_count > 1),我不能直接改!」→ 先分配一个新的空 Block P5,把 P0 的内容整个复制过去,然后自己的 Block Table 里把 L0 改成指向 P5,ref_count(P0) 减 1,最后往 P5 里写新内容。这样其他两条序列的 P0 完全没被动过。
整个过程只复制 1 个 Block(几十 KB),而不是整条序列(可能几 MB),开销极小。
ChatGPT / Claude 类产品每个请求都带同一段几百 token 的 System Prompt:「你是一个有帮助的助手,请用中文回复…」(假设 128 token = 32 个 Block,Block Size=4)。
占,但极其微小,可以忽略不计。计算一下:
Block Table 每个条目 = 1 个整数(逻辑编号 → 物理编号的映射),4 字节。
一条 2048 token 的请求,Block Size=16 → 需要 128 个条目 → 512 字节 = 0.5 KB。
同时 1000 条请求在线 → Block Table 总开销 ≈ 500 KB。
而这 1000 条请求的 KV Cache 本身是 几十 GB。
Block Table 的占比 < 0.001%,ref_count 数组同理(每个物理 Block 4 字节,几 KB 级别),完全可以忽略。
不是的——vLLM 的 Automatic Prefix Caching(APC) 机制让缓存跨 batch 持久化:
每个物理 Block 内容计算一次哈希(例如用 token_ids 的 tuple 作 key),存入一张全局哈希表(在整个 vLLM 进程生命周期内都有效)。只要显存没被驱逐,这个 Block 就一直在那里。
第 2 个请求(batch 2,可能是 1 小时后来的):同样的 System Prompt → 查哈希 → 命中 P0–P31 → 直接复用,0 次重算
第 N 个请求(任意时间):只要 P0–P31 没被驱逐 → 永远命中,永远不重算
不需要提前比对。类比图书馆的索书号:你不需要把两本书逐页对比才能知道它们是不是同一本,只需要看索书号(哈希值)是否相同就行。vLLM 给每个 Block 算一个"指纹",用指纹查表,O(1) 就能知道这块内容有没有被缓存过。
具体怎么算指纹(Block Size = 4,token 用数字 ID 表示):
新请求 B 进来:「你是助手 请帮我 翻译这段 英文内容」——前两块和请求 A 相同
- 每次只查一个哈希表(字典的 key 查找),耗时微秒级,比 Prefill 快 4–5 个数量级
- 哈希是链式的(后一个 Block 的哈希包含前一个),所以「前缀相同」才会哈希相同——不会误判
- 完全不需要 batch 内提前比较,每个请求进来时独立查,互不干扰
- 128 token 的 System Prompt,Block Size=16 → 只查 8 次哈希表,几乎零开销
用 Python 模拟 vLLM 的 Block Table 管理:3 条并发请求,Block Size=4,展示逻辑→物理映射、动态分配、请求完成后物理 Block 回收复用。
from collections import defaultdict
BLOCK_SIZE = 4 # 每个 Block 存 4 个 token 的 KV
TOTAL_PHYS = 9 # 模拟只有 9 个物理 Block(GPU 显存有限)
class BlockAllocator:
"""物理 Block 分配器(空闲链表)"""
def __init__(self, n):
self.free = list(range(n)) # 物理 Block 编号 0..n-1
self.ref_count = defaultdict(int)
def alloc(self):
if not self.free:
raise RuntimeError("OOM: 无空闲物理 Block")
blk = self.free.pop(0)
self.ref_count[blk] = 1
return blk
def free_block(self, blk):
self.ref_count[blk] -= 1
if self.ref_count[blk] == 0:
self.free.append(blk)
print(f" [Allocator] 物理 Block {blk} 已回收,当前空闲: {sorted(self.free)}")
def share(self, blk):
"""共享一个 Block(ref count +1)"""
self.ref_count[blk] += 1
class Sequence:
"""一条请求的 KV Cache 状态"""
def __init__(self, name, allocator):
self.name = name
self.allocator = allocator
self.block_table = [] # 逻辑 Block → 物理 Block 编号
self.filled = [] # 每个逻辑 Block 已填充的 slot 数
self.total_tokens = 0
def append_tokens(self, n_tokens):
"""追加 n_tokens 个 token 的 KV,自动管理 Block"""
for _ in range(n_tokens):
# 如果当前最后一个 Block 已满,分配新 Block
if not self.block_table or self.filled[-1] == BLOCK_SIZE:
phys = self.allocator.alloc()
self.block_table.append(phys)
self.filled.append(0)
print(f" [{self.name}] 分配新物理 Block {phys} "
f"(逻辑 Block {len(self.block_table)-1})")
self.filled[-1] += 1
self.total_tokens += 1
def release(self):
"""请求完成,释放所有物理 Block"""
for phys in self.block_table:
self.allocator.free_block(phys)
self.block_table.clear()
self.filled.clear()
print(f" [{self.name}] 请求完成,全部 Block 已释放")
def status(self):
mapping = [f"L{i}→P{p}({f}/{BLOCK_SIZE})"
for i, (p, f) in enumerate(zip(self.block_table, self.filled))]
return f"{self.name}: tokens={self.total_tokens} [{', '.join(mapping)}]"
# ────────────────────────────────────────────────────
# 模拟 3 条并发请求
# ────────────────────────────────────────────────────
allocator = BlockAllocator(TOTAL_PHYS)
print("=" * 62)
print(f"初始空闲物理 Block: {sorted(allocator.free)}")
print("=" * 62)
# 请求 A:prompt 7 tokens(需 2 个 Block:4 + 3)
print("\n--- 请求 A Prefill(7 tokens)---")
req_a = Sequence("ReqA", allocator)
req_a.append_tokens(7)
print(" ", req_a.status())
# 请求 B:prompt 5 tokens
print("\n--- 请求 B Prefill(5 tokens)---")
req_b = Sequence("ReqB", allocator)
req_b.append_tokens(5)
print(" ", req_b.status())
# 请求 A Decode:再生成 3 个 token
print("\n--- 请求 A Decode(再生成 3 tokens)---")
req_a.append_tokens(3)
print(" ", req_a.status())
# 请求 C:prompt 4 tokens
print("\n--- 请求 C Prefill(4 tokens)---")
req_c = Sequence("ReqC", allocator)
req_c.append_tokens(4)
print(" ", req_c.status())
print(f"\n当前空闲物理 Block: {sorted(allocator.free)}")
print("=" * 62)
print("请求 B 完成,释放内存:")
req_b.release()
print(f"\n请求 B 释放后,空闲物理 Block: {sorted(allocator.free)}")
# 请求 D 进来,复用请求 B 释放的 Block
print("\n--- 请求 D Prefill(6 tokens,复用 ReqB 释放的 Block)---")
req_d = Sequence("ReqD", allocator)
req_d.append_tokens(6)
print(" ", req_d.status())
print("=" * 62)
print("最终所有请求状态:")
for seq in [req_a, req_c, req_d]:
print(" ", seq.status())
print(f"\n剩余空闲物理 Block: {sorted(allocator.free)}")
# 结论:
# - 物理 Block 可被不同请求动态分配/回收,无需连续
# - 请求 D 复用了 ReqB 释放的 Block,GPU 显存零浪费
# - 每条请求最多浪费 1 个 Block 的未填充 slot
运行此代码无需任何依赖,python paged_attn_demo.py 即可。可以看到请求 B 释放后,其物理 Block 立刻被请求 D 复用——这正是 vLLM 显存利用率达 96% 的核心机制。
实测性能数据(来自原论文)
| 实验场景 | vLLM vs Orca (Oracle) | vLLM vs Orca (Max) | vLLM vs FasterTransformer |
|---|---|---|---|
| OPT-13B,单 GPU,ShareGPT | 1.7×–2.7× 更高吞吐 | 2.7×–8× | 最高 22× |
| Beam Search (width=6),OPT-13B | 2.3×(vs 基础采样 1.3×) | – | – |
| KV Cache 有效利用率 | 96.3% | vs 20.4%(Max) | vs 38.2%(Pow2) |
Beam Search 的多条候选路径共享大量前缀 Block(论文实测共享节省内存达 55%),共享的 Block 越多,能装进显存的并发请求就越多,吞吐量提升也越大。相比之下,基础采样每个请求完全独立,没有共享机会。
- Block 内部仍有少量碎片:最后一个 Block 填不满(最多 B-1 个 slot),Block Size 越大碎片越多。论文建议 Block Size 16 作为平衡点。
- 非连续访问的额外开销:Block Table 间接寻址带来额外的内存访问,需要专门的 CUDA Kernel(论文实现了 fused block read + attention kernel)。
- CPU-GPU 传输瓶颈(Swap vs Recompute):见下方详细解释。
首先要理解为什么会触发这个问题:vLLM 同时服务几十上百条请求,GPU 显存(比如 80GB)是有限的。当请求太多、KV Cache 把显存占满时,新来的请求进不来——vLLM 必须把某些正在处理的请求「暂时移走」,腾出空间。问题是:移到哪里?怎么移?
等轮到它了,再从 CPU 搬回 GPU,继续生成
GPU ↔ CPU 之间通过 PCIe 总线传输,带宽约 16–32 GB/s
而 GPU 内部显存带宽高达 2–3 TB/s
差了 100 倍,搬一次 KV Cache 可能要几十毫秒
等轮到它了,把原始 prompt 重新 Prefill 一遍,重新算出 KV
Prefill 计算完全在 GPU 显存里做,速度很快
避免了 PCIe 传输这个瓶颈
论文实测:短序列时 Recompute < Swap 时间
Swap 方案耗时估算:
KV Cache 大小 ≈ 512 token × (LLaMA-2 7B 参数) = 512 × 2 × 32层 × 4096 × 2字节 ≈ 268 MB
PCIe 带宽 16 GB/s → 传输 268 MB 需要 约 17 ms(还回来还要再 17 ms)
Recompute 方案耗时估算:
重新 Prefill 512 个 token,GPU 并行计算,耗时通常 5–15 ms(视 batch size 和 GPU 型号)
→ 短序列时 Recompute 反而更快!频繁 Swap 的 PCIe 往返开销比重算代价更高。
Swap = 把草稿纸拍照备份到手机(CPU RAM),腾出纸继续;需要时再把照片打印出来接着算。
Recompute = 直接把草稿纸撕掉,等需要时从头重推一遍前几步。
如果你前几步推的很快(GPU Prefill 快),重推比等打印机打出来还快——所以论文建议优先用 Recompute。
说得对。CPU RAM 虽然比 GPU 显存大很多,但面对极长序列或超大并发时同样会撑不住:
典型服务器配置:
CPU RAM:64–128 GB
倍数:约 5×
CPU RAM:256–512 GB
倍数:约 4–6×
10 条并发 = 50 GB
CPU RAM 也顶不住
你可能会问:batch 结束后所有请求都完成了,所有 Block 的 ref_count 不都变成 0 了吗?那 APC 的跨 batch 复用从何说起?
答案是:ref_count = 0 只代表「没有人正在使用」,Block 的内容仍然留在显存里,不会主动清除。
这和操作系统的 Page Cache 完全相同:
Block 进入冷缓存池(内容仍在显存)
下一个请求来了 → 检查 hash → 命中 → ref_count 重新 +1 → 直接复用
→ 这就是 APC 跨 batch 复用的原理
按 LRU 驱逐最久未访问的 ref_count=0 Block
这些 Block 的物理空间才真正被回收
→ 这就是③说的「释放空间」
你关掉一个网页标签(ref_count 归零),浏览器不会立刻删除它的缓存。下次打开同一个网址,浏览器先查本地缓存,命中了就直接用(跨 batch 复用)。缓存不够时才按 LRU 清理最久没访问的条目(真正释放)。vLLM 的 Block 管理和这完全一样。
来源:"TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate",Amir Zandieh et al.,Google Research & NYU,arXiv:2504.19874(2025)。
KV Cache 已经存在了——§1 解决了「重复计算」,§2 解决了「内存碎片」。但还有一个问题没解决:KV Cache 太占内存了。一条 LLaMA-2 7B 的请求,128K token 上下文的 KV Cache 就要 64 GB,一张 A100 只够放 1 条。
TurboQuant 的思路是:把每个 KV 向量从 fp16(16 bit/元素)压缩到 2.5–3.5 bit/元素,体积缩减 4–6×,同时保证生成质量几乎不下降。
量化(Quantization)就是把连续的浮点数,映射到有限个离散的「格点」上存储——本质是有损压缩,bit 越少,格点越稀,误差越大,但存储越省。
格点就是量化允许存储的那些离散值——像尺子上的刻度,真实数值只能取最近的一个刻度。
格点的具体数值由两件事决定:① 数据的范围、② 格点的放置策略。
① 先扫描数据,确定范围(min/max)
最小值 = −1.8,最大值 = +1.8(绝大多数值在 −2 到 +2 之间)
→ 量化范围就定为 [−2, +2]
如果范围是 [−100, +100],4 个格点的间距是 66,精度极差
→ 格点位置:−2, −0.67, +0.67, +2
或者更常见的对称写法(以区间中点为格点):
把 [−2, +2] 等分 4 段,每段的中点就是格点:−1.5, −0.5, +0.5, +1.5
数据范围约 [−2, +2] + 4 个格点 + 均匀分布 = 自然得到这几个值。
数据不同、bit 不同,格点就完全不同。
扫描所有坐标值,找到 min = −1.8,max = +1.8
→ 量化范围定为
[−2, +2](稍微留点余量防截断)
2-bit = 4 个格点,在 [−2, +2] 内均匀等分:
4 段区间的中点 →
{ −1.5, −0.5, +0.5, +1.5 }这 4 个值就是全部「格点」,也是量化后允许出现的值。
每个格点对应一个整数编号:−1.5→0,−0.5→1,0.5→2,1.5→3
x = 0.73,与 4 个格点的距离:
|0.73−(−1.5)| = 2.23,|0.73−(−0.5)| = 1.23,|0.73−0.5| = 0.23,|0.73−1.5| = 0.77
最近格点是 0.5,编号 = 2(用 2 bit 存这个编号)
原来要存 fp16(16 bit):
0.73 → 0 01111 0111010111(16 bit)现在只存编号(2 bit):
2 → 10(2 bit)节省了 8×
读到编号 2,查表得格点 0.5 → x̃ = 0.5
量化误差 = |0.73 − 0.5| = 0.23(约 31% 的相对误差——2-bit 精度确实很粗糙)
原来:4096 × 16 bit = 65536 bit = 8 KB
现在:4096 × 2 bit = 8192 bit = 1 KB(压缩 8×),另需存 4 个格点值 = 32 byte(可忽略)
量化听起来简单,难点在哪?
你把一张高清照片(fp16)保存成低质量 JPEG(2-bit),肯定会失真。量化也一样——把每个浮点数四舍五入到最近的整数格点,信息必然丢失。
KV Cache 的量化有两个目标:
- 目标 1 — 量化误差(MSE)要小:还原出的向量要和原始向量尽量接近,L2 距离要小
- 目标 2 — 内积偏差(Bias)要为零:Attention 本质是算 Q·K(内积),量化后算出的内积必须是无偏的,否则 Attention Score 会系统性偏高/偏低,生成质量下降
普通量化(比如压缩模型权重)只需要 MSE 小就够——还原出来的权重接近原始,推理结果就准。
KV Cache 量化不一样:量化后的 K、V 向量不是先"完整还原"再用,而是直接带着误差参与 Attention 计算:
Output = softmax(Score) · Vquantized ← 用的是量化后的 V
只要各 token 分数的相对顺序不变,就能选对"关注哪里"。
如果内积系统性偏小,softmax 权重分布会变平(详见下方分析),所以 Bias = 0 是核心要求。
如果 V 有大误差,加权求和的结果就偏,这个偏差会一层层传播放大。
相对顺序无所谓,但数值得准确——所以 MSE 小是核心要求。
难点:这两个目标天然矛盾。为什么矛盾?核心在于:「最小化 MSE」和「保持内积无偏」要求格点的位置满足两套不同的条件,而这两套条件同时满足不了。
数据大多数值聚集在 0 附近(中间多,极端值少)。MSE 最小化的目标是"让加权平均误差最小"——出现频率高的值权重大,出现频率低的值权重小。
想象格点是「有限的停车位」,数值是「车」。MSE 就是每辆车走到最近停车位的平均距离。
如果 90% 的车停在市中心(数值集中在 0 附近),只有 10% 的车在郊区(极端值),把大部分停车位建在市中心,平均步行距离就更短——哪怕郊区的车要走很远也无所谓,因为它们少。
具体数字:设数据 90% 在 [−0.5, +0.5],10% 在 [±1, ±2],只有 4 个格点:
中间 90% 的值最大误差 0.5
边上 10% 的值最大误差 0.5
加权平均误差 ≈ 0.25
中间 90% 的值最大误差 0.2 ✅
边上 10% 的值最大误差 1.6 ❌
加权平均误差 ≈ 0.2×0.9 + 1.2×0.1 = 0.30
直觉总结:格点是有限资源,MSE 最优 = 按出现频率分配格点,哪里值多哪里格点密——这自然导致中间密、两端稀。
间距均匀,大值 1.4 → 格点 1.5(误差 0.1)
中间密!大值 1.4 → 最近格点 0.8(误差 0.6)
MSE 最优格点把所有较大的值都映射到比实际小的格点上(因为格点集中在中间,边上稀疏)。量化后的向量 x̃,整体上每个坐标都比原始 x 偏小——向量「缩短」了,像是被朝原点方向压缩了一下。
真实内积 = 1×1.4 + 1×0.1 = 1.5
MSE 最优格点 { −0.8, −0.2, +0.2, +0.8 } 量化后:
1.4 → 格点 0.8(大值被拉小)
0.1 → 格点 0.2(小值稍微变大)
量化内积 = 1×0.8 + 1×0.2 = 1.0(比真实值 1.5 小了 33%!)
所有内积都乘了同一个系数(约 0.637),相当于给 softmax 升温——高分 token 的权重被稀释,低分 token 的权重被抬高,权重分布变平。
量化后 ×0.637:[6.37, 3.18, 0.64] → softmax → [0.961, 0.036, 0.003](稍微散了)
❓ 那用温度系数缩放回来行不行?
理论上可以,但有两个障碍:
- 偏差系数不是固定常数——不同层、不同 head、不同 token 的 KV 分布不同,偏差系数也不同,没有统一的补偿值
- 需要知道偏差才能补偿——如果要在线估计偏差系数,开销不小,还不如从根源解决
- MSE 最小要求格点往数值密集的中间靠——这意味着大值会被往中间压
- 内积无偏要求大值和小值的相对比例在量化后保持不变——这需要格点均匀,不能往中间偏
- 两个要求对格点的位置提出了相反的要求,所以天然矛盾
点击展开每种方案的详细分析 ↓
min=-0.01, max=100.0 → 量化范围 = 100.01
每个格点间距 = 100.01 / 255 ≈ 0.392
x[1]=0.01 → round(0.01/0.392) = round(0.026) = 0 → 还原 = 0.000
x[2]=0.02 → round(0.02/0.392) = round(0.051) = 0 → 还原 = 0.000
x[1] 和 x[2] 都被量化成 0,精度完全损失!
• 实现极简,一行代码
• 量化/反量化速度极快
• MSE(L2误差)表现不错
硬伤①:内积有偏
线性缩放后量化 → 反量化值是偏置后的值 → ⟨y, x̃⟩ ≠ ⟨y, x⟩ 的无偏估计,Attention 分数系统性偏移
硬伤②:outlier 拉垮全局
一个 100 的异常值把格点间距拉到 0.39,正常值 0.01~0.02 之间的所有差异全部消失
• 精度高(用数据学到的 codebook,可以适配实际分布)
• 内积估计快(查 LUT)
• 工业界 ANN(近似近邻搜索)事实标准
K-Means 要跑完整训练集,每次新数据都要重训;
LLM 推理时 KV Cache 是一边生成一边写入的流式数据——第一个 token 写入时根本没有「整批数据」,无法提前建 codebook。
实测建索引时间(论文 Table 2):
d=1536 时 PQ 建索引需 239 秒,TurboQuant 只需 0.0013 秒
最大问题:GPU 上跑不快
RabitQ 的格点搜索算法需要 binary search + recursive subdivision,这类分支密集的控制流在 GPU 上效率极低。GPU 擅长的是矩阵乘法这类「所有线程做同样操作」的规则并行,遇到分支就会 warp divergence(同一 warp 内的线程走不同分支,实际串行执行)。
论文实测(Table 2):d=1536 时 RabitQ 量化 100K 向量需 2268 秒,TurboQuant 只需 0.0013 秒(快 174 万倍)。
• 有理论保证的 MSE 下界
• 不需要离线建 codebook(online)
• 实际召回率(Recall)优于 PQ
• 无 vectorized GPU 实现,速度慢到不可用(2268s vs 0.001s)
• 内积估计有偏(无残差补偿)
• 论文也指出其实际 bit 消耗比声称的更多(额外开销未计入)
| 方案 | Online? | 内积无偏? | GPU 友好? | 核心问题 |
|---|---|---|---|---|
| KIVI(朴素标量) | ✅ | ❌ | ✅ | 内积有偏 + outlier 脆弱 |
| PQ | ❌ 需离线K-Means | 近似 | ✅(查 LUT) | 无法实时量化流式 KV Cache |
| RabitQ | ✅ | ❌ | ❌ 无向量化实现 | GPU 慢 174 万倍,无法实用 |
| TurboQuant | ✅ | ✅ | ✅ 矩阵乘+查表 | 三项全满足 |
核心技巧:随机旋转消灭 Outlier
TurboQuant 的第一个关键洞察:量化难,是因为高维向量的坐标分布极度不均匀——有些坐标很大(outlier),有些很小,强行用同一个量化范围会浪费精度。
解决办法:先随机旋转,再量化。
Π 是一个 d×d 的矩阵(d = 向量维度),乘上去的效果就是旋转这个向量——像把一根棍子在空间里随机转一个角度。
关键性质:
- 长度不变:旋转不改变向量的 L2 范数(‖Π·x‖ = ‖x‖)——信息没丢,只是换了个方向
- 能量被打散:原来集中在少数维度的大数值,旋转后会分散到所有维度上,每个维度分到大约相同的能量
- 可逆:Π 的逆矩阵就是它的转置 Π⊤,量化完可以旋转回来(近似还原)
以 2 维向量为例(真实场景是 4096 维,原理完全一样):
Step 1:随机生成一个正交矩阵 Π最简单的正交矩阵是旋转矩阵,旋转角度 θ:
Π = [ cos θ −sin θ ]
[ sin θ cos θ ]
取 θ = 30°,代入 cos30°≈0.866,sin30°=0.5:
Π = [ 0.866 −0.5 ]
[ 0.5 0.866 ]
Π·x = [ 0.866×10 + (−0.5)×2 ] = [ 8.66 − 1.0 ] = [ 7.66 ]
[ 0.5×10 + 0.866×2 ] = [ 5.00 + 1.73 ] = [ 6.73 ]
旋转后:Π·x = [7.66, 6.73](两个坐标都有值,不相等,但量级相近)
旋转后 ‖Π·x‖ = √(7.66² + 6.73²) = √(58.7 + 45.3) = √104 ≈ 10.2 ✅
长度完全不变!能量只是在两个坐标之间「重新分配」了。
Π⊤ = [ 0.866 0.5 ]
[ −0.5 0.866 ]
Π⊤ · [7.66, 6.73]:
第1行:0.866×7.66 + 0.5×6.73 = 6.63 + 3.37 = 10.0
第2行:−0.5×7.66 + 0.866×6.73 = −3.83 + 5.83 = 2.0
完美还原回 [10, 2] ✅(真实量化中会有轻微误差,因为 Π·x 量化时有损失)
现在看具体例子。假设原始 KV 向量是 4 维:x = [100, 0.01, 0.01, 0.01]
问题:x[0] = 100 是个 outlier,其余坐标约等于 0。
量化范围:[−100, 100](要覆盖最大值)
4 个格点 = 范围 ÷ 3 段:
{ −100, −33, +33, +100 }
x[0]=100 → 格点 100 ✅ 误差 0
x[1]=0.01 → 最近格点是 −33 ❌ 误差 33!
x[2]=0.01 → 最近格点是 −33 ❌ 误差 33!
x[3]=0.01 → 最近格点是 −33 ❌ 误差 33!
(正负交替,幅度各异,但量级相近)
验证范数:√(65.2²+30.7²+61.6²+31.8²) = √(4251+942+3795+1011) = √10000 = 100 ✅
min = −65.2,max = +61.6
量化范围:[−68.5, +68.5](远小于原来的 [−100, +100]!)
4 个格点:{ −51.3, −17.1, +17.1, +51.3 }
(范围 137 ÷ 4 段,中点:±17.1,±51.3)
x[0]=−65.2 → 格点 −51.3 误差 13.9(vs 0 ← 这里旋转前精确,旋转后反而有误差,但其它坐标大幅改善)
x[1]=30.7 → 格点 +17.1 误差 13.6(vs 33!)✅
x[2]=61.6 → 格点 +51.3 误差 10.3(vs 33!)✅
x[3]=−31.8 → 格点 −17.1 误差 14.7(vs 33!)✅
关键在于:量化范围由最大坐标绝对值决定,而旋转把这个最大值"摊薄"了。
原始向量 x = [100, 0.01, 0.01, 0.01],max|x[i]| = 100,量化范围必须覆盖到 ±100。
旋转后 Π·x = [−65.2, 30.7, 61.6, −31.8],max|y[i]| = 65.2,量化范围只需覆盖 ±68.5。
为什么 max 会从 100 降到 65?
旋转前:能量 100² = 10000 全集中在一个坐标 → 这个坐标值必须是 100。
旋转后:能量 10000 被分散到 4 个坐标 → 每个坐标平均承担 10000/4 = 2500,即 √2500 = 50。
最大坐标不可能超过 ‖x‖ = 100(所有能量都在这一个坐标的极端情况),
但分散后最大坐标期望只有 ‖x‖/√d ≈ 100/√4 = 50——比原来小 √d 倍。
实际结果 65.2 稍高于期望 50,是因为随机旋转有波动,不是精确均分。
不是——旋转只解决了 MSE,Bias=0 由另一个机制单独保证。 两个目标用两套机制分别解决:
Lloyd-Max 在均匀分布上放最优格点。
共同保证量化误差最小化。
QJL 随机投影 1-bit,专门保证内积无偏。
旋转本身不能保证内积无偏。
数学依据:旋转后每个坐标近似服从 Gaussian 分布且近似独立——这让"对每个坐标用相同的量化范围独立量化"变成最优策略,也是 Lloyd-Max 最优格点可以直接套用的前提。
MSE 量化器:像"把秤盘刻度摆均匀"
旋转后,每个坐标的分布已知(Beta 分布 / Gaussian),问题变成:怎么放量化格点,让平均误差最小?
旋转后,坐标值服从 Gaussian 分布,大多数值集中在 0 附近,极端值很少。
中间密集区的值 → 0.1 被分配到 0.5(误差 0.4)
浪费了大量精度在极少出现的边缘区域
常见的中间值 → 量化误差更小
离均值越近,精度越高
Lloyd-Max 算法:迭代地把格点放在每个区间的质心处(像 1D K-Means)。TurboQuant 预先把 1/2/3/4 bit 的最优格点全算好、存成 codebook,推理时直接查表,不需要现场计算。
TurboQuant 的 MSE 与信息论下界只差 ≈2.7 倍常数,而现有方法差距往往超过 10×。
内积量化器:两阶段消除偏差
TurboQuant 的解法是两阶段量化——用 (b−1) bit 的 MSE 量化做主体,再用 1 bit 的 QJL 量化补偿残差,合计 b bit,同时保证 MSE 小 + 内积无偏。下面用具体数字完整走一遍。
Query 向量(当前 token): y = [+0.70, +0.50, −0.30, +0.80]
目标:估计内积 ⟨y, x⟩(真实值 = −0.1000)
Lloyd-Max 为 Gaussian 分布算出的 4 个最优格点:{−0.8504, −0.2549, +0.2549, +0.8504}
x[1]=−0.32 → 最近格点 −0.2549(编号 01) 残差 r[1] = −0.32 − (−0.2549) = −0.0651
x[2]=+0.61 → 最近格点 +0.8504(编号 11) 残差 r[2] = +0.61 − 0.8504 = −0.2404
x[3]=−0.44 → 最近格点 −0.2549(编号 01) 残差 r[3] = −0.44 − (−0.2549) = −0.1851
x̃ = [+0.8504, −0.2549, +0.8504, −0.2549]
r = [−0.0004, −0.0651, −0.2404, −0.1851]
‖r‖ = √(0.0004²+0.0651²+0.2404²+0.1851²) = 0.3103(也需存储,1个标量)
Stage 1 算出的 ⟨y, x̃⟩ = +0.0088,但真实内积是 −0.1000——相差了 0.1088,这个误差就是 ⟨y, r⟩(r 是残差向量)。
所以 Stage 2 的唯一目的是:把 ⟨y, r⟩ 估计出来,加回去补偿偏差。
为什么不直接存 r,而要用 QJL?
直接存 r 需要存一整个向量(跟存 x 一样大,完全没节省)。
QJL 的思路:⟨y, r⟩ 是一个标量,可以用「问 k 个随机方向:r 在这个方向上是正还是负?」来无偏估计。每个方向只需 1 bit,总共只用 k bit 就能拿到这个标量的无偏估计。
那 S 本身不需要存吗?S·r 每个 KV 都要算,不浪费算力吗?
S 是从固定随机种子(如 seed=42)生成的,所有 KV 向量共享同一个 S,不需要存储——随时可从种子重生成,存储开销 O(1)。
S·r 的计算开销确实存在——每个新 KV 向量写入 Cache 时都要算一次(k×d 次乘加,k=d 时约等于一次矩阵乘法)。这是真实的计算代价,不是免费的。
但这是一个刻意的 trade-off:用计算换存储。原因在于 KV Cache 的瓶颈是内存带宽而不是计算:
Attention 推理的瓶颈是"把 KV Cache 从 HBM 搬到计算单元",不是矩阵乘法本身。
QJL 让每个 KV 从 fp16(16 bit)压到 ~3 bit,内存读取量减少 5×,带宽压力大幅下降。
写入时多的那点计算(S·r),与节省的带宽相比代价很小——整体反而更快。
r = [−0.0004, −0.0651, −0.2404, −0.1851]
s₁·r = 0.50×(−0.0004) + (−0.80)×(−0.0651) + 0.30×(−0.2404) + 0.60×(−0.1851)
= −0.0002 + 0.0521 − 0.0721 − 0.1111
= −0.1313 → sign = −1 (只存这 1 bit)
s₃·r = −0.067 → sign = −1
s₄·r = −0.095 → sign = −1
总存储:8 bit(主体)+ 4 bit(残差)= 12 bit = 3 bit/坐标 ✅
= 0.595 − 0.127 − 0.255 − 0.204 = +0.0088(MSE 项,有偏)
第二项:QJL 估计 ⟨y, r⟩
S·y 只算一次,对整个序列所有 KV 向量复用:
先对 y 也做 sign 投影:s₁·y=+0.340→+1,s₂·y=−0.740→−1,s₃·y=+1.370→+1,s₄·y=−0.130→−1
乘积:(+1×−1), (−1×−1), (+1×−1), (−1×−1) = −1, +1, −1, +1
平均乘积 = 0.000
QJL 估计 ⟨y,r⟩ ≈ (π/2) × ‖r‖ × ‖y‖ × 0.000 = (π/2) × 0.3103 × 1.212 × 0 = 0.0000
真实内积 = −0.100
误差 = 0.109 ← k 太少导致方差大,不是偏差
→ k 越大,方差越小,估计越准 → 无偏(期望 = 真实内积)✅
乘以 (π/2)×‖r‖×‖y‖ 后,期望 = ‖r‖×‖y‖×cos(θyr) = ⟨y, r⟩
加上 ⟨y, x̃⟩,总期望 = ⟨y, x̃⟩ + ⟨y, r⟩ = ⟨y, x̃+r⟩ = ⟨y, x⟩ ✅
- MSE 量化保证的不是「r 很小」,而是「‖r‖ 精确已知」——有了这个缩放因子,QJL 的方向信息才能被还原成正确量纲的内积估计
- QJL 的方差与 ‖r‖ 正相关:残差越小(bit 越高),估计方差越小;2-bit 残差约 0.31,4-bit 残差只有 ~0.05,所以高 bit 估计更稳定
- k(随机方向数)越大,方差越小;实际 TurboQuant 用 d(向量维度)个方向,d=4096 时 k 足够大
速度:比 PQ 快 10 万倍
核心操作只有两步:矩阵乘法(Π·x,即旋转)+ 查表(找最近格点)。两步都高度并行、完全向量化,GPU 天然擅长。
反观 Product Quantization(PQ):需要先离线跑 K-Means 聚类建 codebook,每次有新数据还要重新聚类,无法实时处理流式 KV Cache。
实测量化时间(4 bit,100K 向量):
TurboQuant 比 PQ 快约 24 万倍,比 RabitQ 快约 227 万倍——完全满足实时 KV Cache 场景。
实验结果:4× 压缩,质量无损
实验 1:Needle-in-a-Haystack(大海捞针)
测试方法:在一个超长文档里藏一句话("needle"),让 LLM 回答这句话的内容(recall score)。上下文长度从 4K 到 104K token,越长越难记。
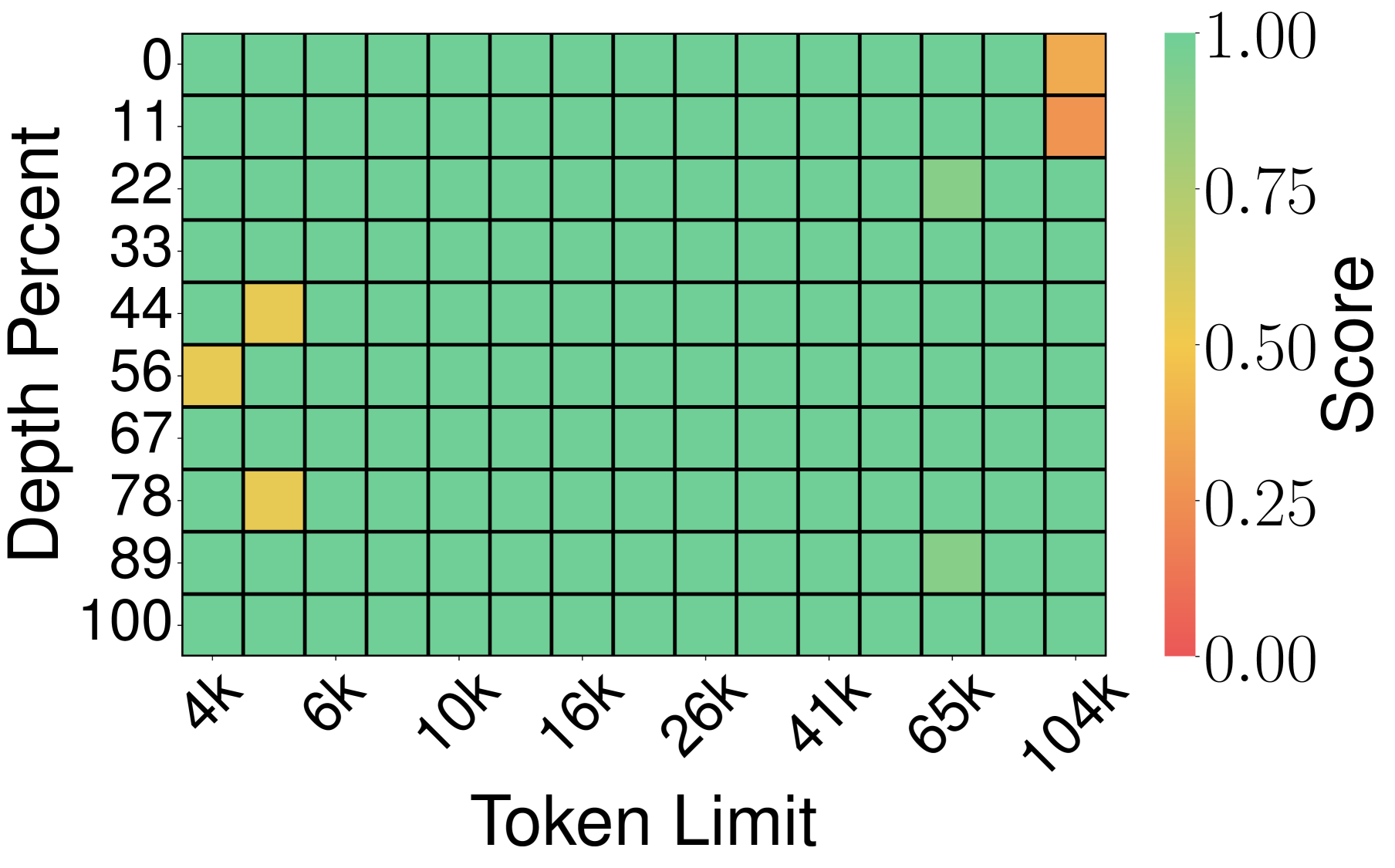
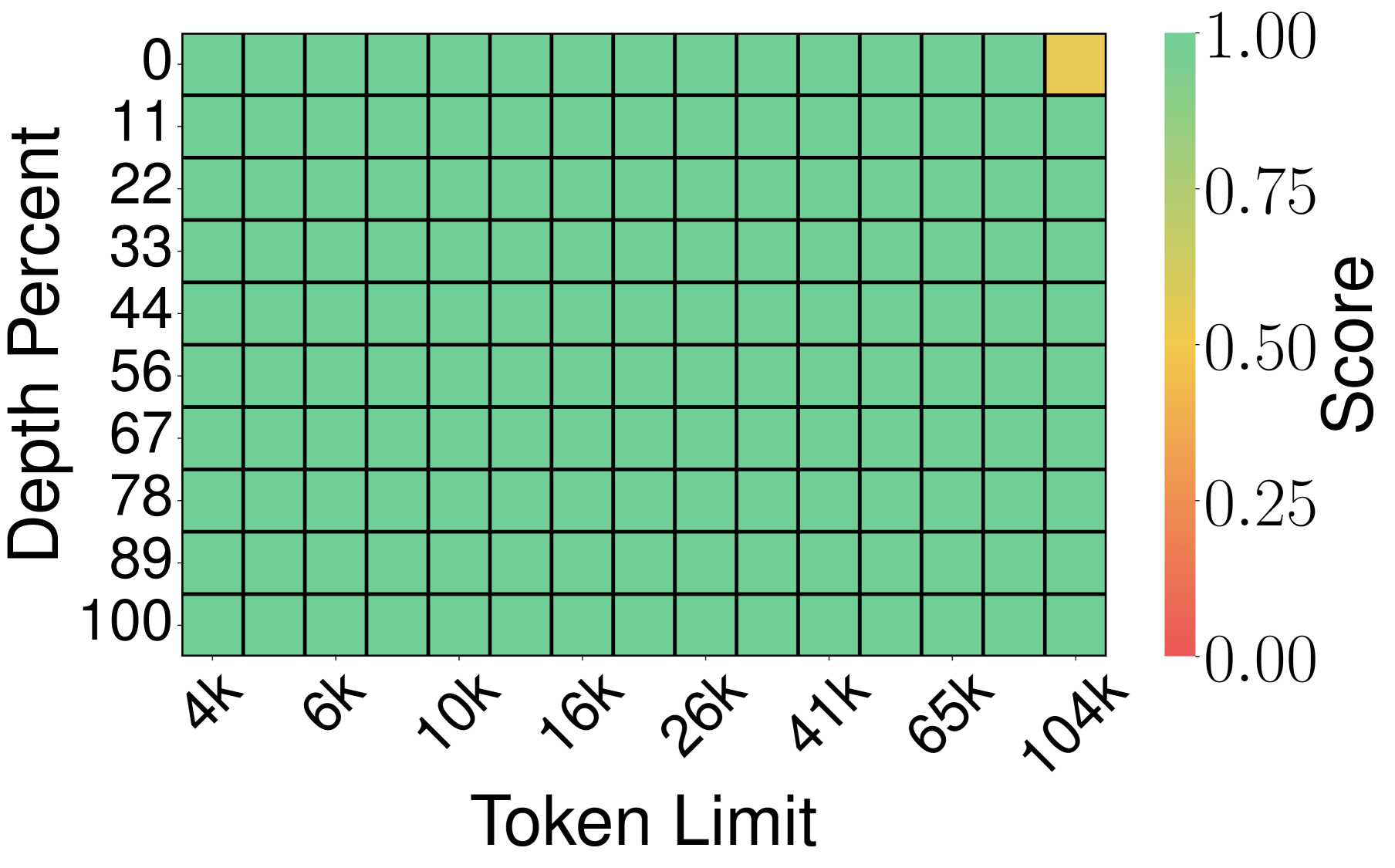
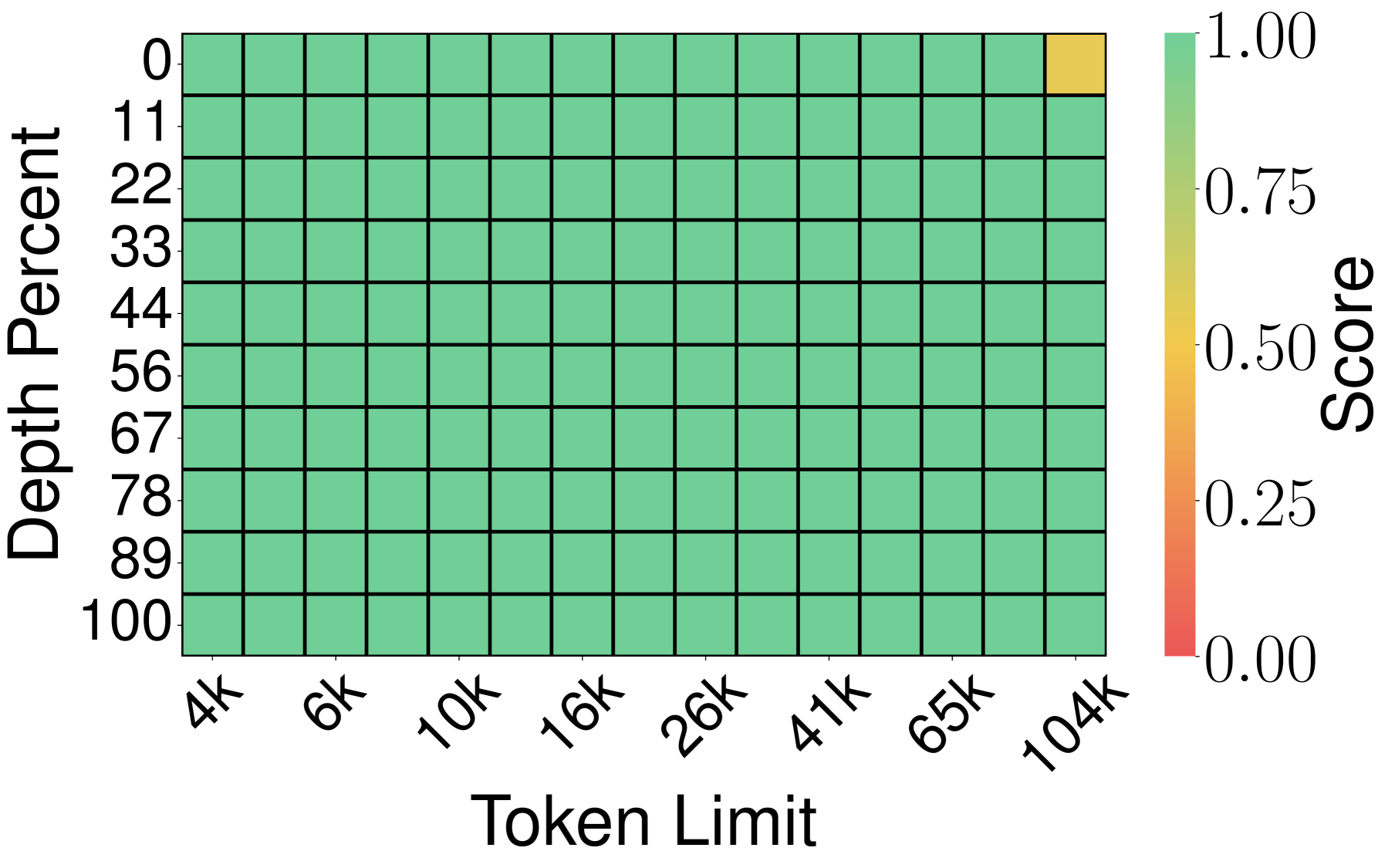
实验 2:LongBench-E(综合长文本基准)
| 方法 | KV 位宽 | 压缩比 | SingleQA | MultiQA | 摘要 | 代码 | 平均分 |
|---|---|---|---|---|---|---|---|
| Full Cache(基线) | fp16 | 1× | 45.29 | 45.16 | 26.55 | 46.28 | 50.06 |
| KIVI | 3 bit | ~5× | 43.38 | 37.99 | 27.16 | 44.68 | 48.50 |
| KIVI | 5 bit | ~3× | 45.04 | 45.70 | 26.47 | 46.41 | 50.16 |
| PolarQuant | 3.9 bit | ~4× | 45.18 | 44.48 | 26.23 | 45.24 | 49.78 |
| TurboQuant(我们) | 2.5 bit | 6.4× | 44.16 | 44.96 | 24.80 | 45.76 | 49.44 |
| TurboQuant(我们) | 3.5 bit | 4.6× | 45.01 | 45.31 | 26.00 | 46.17 | 50.06 |
结论:TurboQuant 3.5 bit 在 4.6× 压缩下,LongBench 平均分与 Full Cache 完全持平(50.06 = 50.06);即使 2.5 bit 压缩 6.4×,平均分仅下降 0.62 分,远优于 KIVI 5 bit(3× 压缩)的同等精度。
放在整体 KV Cache 优化体系里怎么看?
从模型结构入手,减少 KV 头数量
压缩比:2–8×
需要重新训练
减少内存碎片,提高利用率
吞吐量:2–4×
不减少内存总量
每个 KV 向量从 fp16 压到 2–4 bit
压缩比:4–6×
无需重新训练,在线实时
三者可以叠加使用:GQA(减少头数)+ vLLM(分页)+ TurboQuant(量化)= KV Cache 内存可以压缩到原始的 1/20 以下,支持更长上下文和更大 batch size。
- 量化 vs 精度 trade-off 仍存在:2.5 bit 时摘要任务下降约 1.75 分(26.55→24.80),说明语义高密度任务对量化更敏感
-
2.5 / 3.5 bit 是「平均 bit 数」,不是单个值用了小数 bit(来自论文 Section 4.3)
做法:把 KV 向量的 128 个坐标按历史上是否出现过极大值,分成 outlier 通道 和 普通通道 两组,对两组各自独立地跑完整的 TurboQuant 流程,只是 bit 预算不同:2.5-bit 设置(论文原文示例):为什么要分组?outlier 坐标值很大,1-bit MSE 的 2 个格点根本夹不住,残差会极大,QJL 方差也会爆炸;给它分配 3-bit(2-bit MSE = 4 个格点)代价只多 1 bit,但残差会大幅缩小。这与 QuaRot、LLM.int8() 等先前工作的 outlier 处理思路一致(论文原文注引 [63, 51])。
• 32 个 outlier 通道 → 3-bit TurboQuant_prod = (3−1)-bit MSE + 1-bit QJL
• 96 个普通通道 → 2-bit TurboQuant_prod = (2−1)-bit MSE + 1-bit QJL
加权平均:(32×3 + 96×2) / 128 = 288/128 = 2.25 bit(论文写 "= 2.5",实为笔误)
关键:普通通道的 2-bit 不是裸 2-bit 量化! 它是 1-bit MSE(只有 ±√(2/πd) 两个格点)+ 1-bit QJL 残差——同样有 QJL 保证内积无偏,只是格点更稀疏。 - 随机旋转矩阵 Π 和投影矩阵 S 的存储:两个 d×d 矩阵(d=4096 时各约 32 MB),不是很大但也不能忽略
- 理论 vs 实际 gap:MSE 离理论下界还差 ≈2.7 倍常数,意味着在相同精度下还有约 1.4 bit 的改进空间(理论最优 2.5 bit 能做到 TurboQuant 3.5 bit 的效果)
容量大(40~80 GB),但位于芯片外部,读写需要走内存总线。A100 带宽约 2 TB/s,听起来快,但相对于 Tensor Cores 几百 TFLOPS 的算力,根本喂不饱——这就是「内存墙」。
焊在 GPU 芯片上,离计算单元只有几纳米距离。容量极小(每 SM 约 256 KB,全 GPU 合计 ~20 MB),但带宽高达 10~20 TB/s,比 HBM 快 5~10 倍。
S = QKᵀ 写 HBM → 读出做 softmax → 写 P 回 HBM → 读 P 和 V 算 O。中间矩阵 S/P 各 64 MB(n=4096, fp16),每次都走慢速 HBM,带宽全浪费在搬数据上。
标准 Attention 的瓶颈在哪?
标准 Attention 的复杂度是 $O(n^2)$,但实际瓶颈不是算力,而是内存带宽(Memory Bandwidth)。
标准 Attention 计算流程:
GPU 的 SRAM 其实类似 CPU 的 L1 Cache——它是自动管理的工作区,不是你手动放进去的存储空间。
当 GPU 执行一个 CUDA kernel(如矩阵乘法 S=QKᵀ),硬件会自动把需要的数据以「小块(tile)」为单位从 HBM 搬到 SRAM,计算完写回 HBM,再搬下一块。你不可能也不需要把 Q(1 MB)+ K(1 MB)整个塞进去——它们是流式处理的。
标准 Attention 的 PyTorch 实现里,每一步是一个独立的 CUDA kernel:
kernel2: P = softmax(S) # 重新从 HBM 读回 S,算完再写 P 到 HBM
kernel3: O = P @ V # 重新从 HBM 读回 P 和 V,算完写 O 到 HBM
FlashAttention 把 Q/K/V 分成小块(每块能放进 SRAM),在同一个 CUDA kernel 里完成 QKᵀ + softmax + PV 的全部计算:
for each K, V tile:
从 HBM 读一块 K_tile(几 KB)到 SRAM
计算 S_tile = Q_tile @ K_tile.T ← SRAM 内完成
更新 online softmax(维护 max, sum)
从 HBM 读一块 V_tile 到 SRAM
累加 O_tile += softmax_tile @ V_tile ← SRAM 内完成
把最终 O_tile 写回 HBM ← 只在最后写一次!
问题:中间矩阵 $S$(大小 $n \times n$)和 $P$(大小 $n \times n$)需要反复在 HBM(高带宽显存,慢)和 SRAM(片上缓存,快但小)之间搬运。对于 $n=4096$,$S$ 矩阵大约 64 MB(fp16),每次都要完整写入和读出 HBM,IO 成本极高。
Tiling(分块)原理
FlashAttention 的核心思想是 Tiling(分块计算):把 Q、K、V 矩阵分成小块,每次只把一小块加载到 SRAM,在 SRAM 内完成该块的全部计算(包括 softmax 和加权求和),再写回 HBM。这样整个 Attention 的 HBM IO 从 $O(n^2)$ 降到 $O(n^2/M)$。
PyTorch 里
S = Q @ K.T 是一个 CUDA kernel,softmax(S) 又是一个 kernel,O = P @ V 又是一个。kernel 结束时 SRAM 被自动清空(下一个 kernel 要用 SRAM),所以 S(32 MB)必须写到 HBM,下一个 kernel 启动再从 HBM 读回。
→ 写 S + 读 S + 写 P + 读 P = 128 MB 的浪费
把 Q/K/V 按行分成大小为 $B_r \times B_c$ 的 tile,在同一个 CUDA kernel 里一口气完成 QKᵀ + softmax + PV。
S_tile 和 P_tile 只存在于 SRAM 里,用完覆盖。最终 O_tile 才写一次 HBM。
→ HBM IO 降到 ~3 MB(仅读 Q/K/V,写 O 各一次)
完整数值计算演示(n=4,d=2,tile 大小 2×2)
下面的演示板把 Q/K/V 矩阵始终展示在左侧,点击「下一步」逐步推进,当前处理的 tile 会高亮,右侧实时更新 SRAM 状态与计算结果。
| 行 | d=0 | d=1 | 说明 |
|---|---|---|---|
| Q[0] | 2 | 1 | token 0 |
| Q[1] | 1 | 3 | token 1 |
| Q[2] | 3 | 2 | token 2 |
| Q[3] | 1 | 2 | token 3 |
| 行 | d=0 | d=1 | 说明 |
|---|---|---|---|
| K[0] | 1 | 2 | token 0 |
| K[1] | 3 | 1 | token 1 |
| K[2] | 2 | 4 | token 2 |
| K[3] | 4 | 1 | token 3 |
| 行 | d=0 | d=1 | 说明 |
|---|---|---|---|
| V[0] | 3 | 0 | token 0 |
| V[1] | 1 | 4 | token 1 |
| V[2] | 0 | 2 | token 2 |
| V[3] | 5 | 1 | token 3 |
SRAM 每次只能装 2 行 × 2 列 的 tile(B_r=2, B_c=2)。
点击「下一步」开始演示。
Q[0:2]
—
—
—
FlashAttention 用 rescale = \(e^{m_\text{old} - m_\text{new}}\) 把旧块统一换基底, 让所有块的 unnormalized 权重可以直接相加;最后一次 除以 \(\ell^*\)(所有块贡献之和)完成归一化, 数学上与"看完全部 key 再做一次 softmax"完全相同,没有任何近似。
| 操作 | 标准 Attention | FlashAttention |
|---|---|---|
| 读 Q/K/V | 3次 | 5次(分批读) |
| 写/读 S(中间矩阵) | 写1+读1 = 2次 | 0次(只在 SRAM) |
| 写/读 P(softmax 后) | 写1+读1 = 2次 | 0次(只在 SRAM) |
| 写 O(最终输出) | 1次 | 1次 |
| HBM 总 IO | ~128 MB | ~6 MB |
验证:标准 Attention O[0] = [0.715, 0.570],FlashAttention O[0] = [0.716, 0.571](误差 <0.001,来自 scale≈0.707 的近似)。数学完全等价,仅 HBM IO 不同。
SRAM 能装多大的 tile?实际数字
FlashAttention 的 IO 复杂度
| 方案 | HBM 读写量 | SRAM 需求 | 速度(相对) |
|---|---|---|---|
| 标准 Attention | $O(n^2)$(中间矩阵 S、P 反复读写) | $O(n^2)$(需要存完整 S) | 1× |
| FlashAttention v1 | $O(n^2 / M)$(M 为 SRAM 大小) | $O(M)$(只存当前块) | 2-4× |
| FlashAttention v2 | 同 v1,但减少 non-matmul FLOPs | 同 v1 | 2× vs v1 |
| FlashAttention v3 | 同 v2,针对 Hopper GPU 优化 | 同 v1 | 1.5-2× vs v2 |
各版本核心改进
v1 的核心贡献就是上面演示的那套机制:把 QKV 分块加载到 SRAM,用 Online Softmax 逐块合并,全程不把中间矩阵 S/P 写回 HBM。IO 复杂度从 O(n²) 降到 O(n²/M)(M = SRAM 大小)。序列长度 1K 时约快 3×,2K 时快 5×,因为 IO 省得越来越多。
序列 1K:约快 3×
序列 2K:约快 5×
训练显存:节省 5–20×(省去了 n×n 反向 Attention 矩阵)
v1 的瓶颈不在 HBM IO 了,而在 GPU 的并行利用率太低。v2 针对 GPU 线程组织方式做了深度重构。
但多个 warp 的 softmax 分母 ℓ 要合并,
需要 warp 间同步(cross-warp reduce),
同步本身有开销,且 warp 等待对方会空转。
非矩阵乘法操作(rescale、softmax 合并)占了约 40% 的运行时间。
对应同一批 K/V(所有 warp 共读),
每个 warp 的 softmax 完全独立,无需 warp 间同步。
warp 之间从「竞争同一份 softmax 状态」变成「各管各的 Q 行」,
GPU 流水线效率大幅提升。
乘 K[0:2]
→ 必须 reduce 合并 ℓ_a+ℓ_b → 才能写 O[token1,2]
→ 各自直接进入第二批,无需等待
乘 K[2:4]
v2 的第一批:warp0 算 token1,2×K[0:2],warp1 算 token3,4×K[0:2]——负责的 token 不同,所以 m 和 ℓ 天然属于不同 warp,根本不需要合并。
第二批:两个 warp 各自对自己负责的 token 继续算 K[2:4],rescale 合并之前的局部结果,全程在 warp 内部完成,直接写出最终 O。
v2 解决了并行化问题,v3 针对 H100(Hopper 架构)的新硬件特性做深度优化,目标是让矩阵乘和 softmax 的计算时间完全重叠,不再串行等待。
读 K/V → 算 QKᵀ(矩阵乘)→ 等矩阵乘完成 → softmax rescale → 读下一块 K/V → ...
「等矩阵乘完成」和「读数据」两件事是串行的,GPU 的矩阵乘单元(Tensor Core)在等数据时空转,数据加载单元在等矩阵乘时也空转。
原来:「CPU 发指令 → 等搬运完成 → 再算」(Tensor Core 空等)
TMA 后:「后台异步搬下一块数据,同时 Tensor Core 算当前块」
效果:数据搬运和矩阵乘完全重叠(overlap),消灭等待时间。
v3 把 WGMMA 和 softmax 的 rescale 计算交错执行(ping-pong 缓冲区),矩阵乘算第 i 块时,softmax 同时处理第 i-1 块的结果。
效果:有效消除 softmax 的计算延迟。
标准 Attention 反向传播时需要重新存储 $n \times n$ 的 Attention 矩阵 $P$,这是训练时显存暴涨的主因。FlashAttention 通过重计算(recomputation)在反向传播时重新从原始 Q/K/V 算出 $P$,不需要存储,训练时显存节省约 10-20×。
- 只能处理 标准 Causal / Bidirectional Attention,不支持所有 Attention 变体(如稀疏 Attention、线性 Attention 需要单独实现)
- SRAM 大小是硬件固定的,分块大小受限,极长序列(>100K)仍然有瓶颈
- 需要定制 CUDA kernel,跨平台移植成本高(TPU 需要 Pallas,Apple Silicon 需要 Metal)