一句话总结
TIGER 把推荐系统的召回阶段从"向量查找最近邻"改造为"自回归生成下一个 item 的 Semantic ID",核心是用 RQ-VAE 为每个 item 分配一个有语义层级的离散 token 序列,从而让 Transformer 的记忆本身成为检索索引。
背景与动机
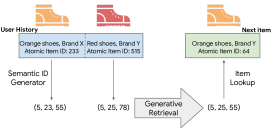
传统推荐系统的召回阶段通常依赖双塔模型(Dual Encoder):用户 tower 和 item tower 各自输出 embedding,再用近似最近邻(ANN)检索候选集。这套范式经历了多年验证,但暗藏几个结构性问题:
- item ID 是随机符号:学到的 embedding 无法跨 item 共享知识,相似 item 只靠协同过滤隐式关联。
- 需要维护外部索引:每次 item 集合更新,都要重新构建 ANN 索引,工程成本高。
- 冷启动问题严重:新 item 没有历史,ANN 无法检索到它。
- 多样性控制困难:ANN 本质是找最相似,不容易调节结果的多样性。
这和 NLP 中的生成式文档检索(DSI、NCI)思路一致,TIGER 是第一篇把这套范式搬进推荐系统的工作。
方法详解
TIGER 分两个阶段:先为每个 item 生成 Semantic ID,再在 Semantic ID 序列上训练 Seq2Seq 推荐模型。
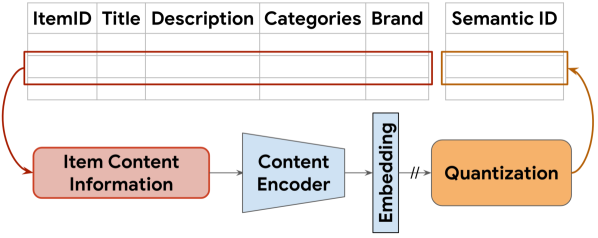
阶段一:Semantic ID 生成
给定 item 的内容特征(标题、描述、品类等),用预训练文本编码器(如 SentenceT5)生成 $d$ 维语义 embedding $\mathbf{x} \in \mathbb{R}^d$,再用 RQ-VAE 将其量化为长度 $m$ 的 codeword 元组 $(c_0, c_1, \ldots, c_{m-1})$,即该 item 的 Semantic ID。
核心要求:相似内容的 item 应有重叠的 Semantic ID。例如,Semantic ID 为 $(10, 21, 35)$ 的 item 应比 ID 为 $(10, 23, 32)$ 的 item 更接近 $(10, 21, 40)$。
RQ-VAE 量化原理
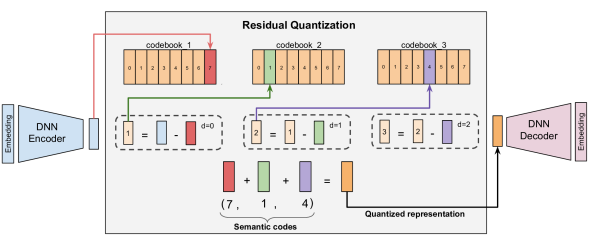
Residual-Quantized VAE 用残差迭代量化生成层级 token。它由编码器、残差量化器、解码器三部分组成:
编码器将输入 $\mathbf{x}$ 映射为潜变量 $\mathbf{z} := \mathcal{E}(\mathbf{x})$,然后按以下方式逐层量化:
第 $d=0$ 层:初始残差 $\mathbf{r}_0 := \mathbf{z}$,从 codebook $\mathcal{C}_0 = \{\mathbf{e}_k\}_{k=1}^{K}$ 中找最近向量:
$$ c_0 = \arg\min_{k} \|\mathbf{r}_0 - \mathbf{e}_k\| $$- $c_0$:第 0 层的 codeword 索引(即 Semantic ID 第一位)
- $\mathbf{r}_0$:第 0 层的残差,等于编码器输出 $\mathbf{z}$
- $\mathbf{e}_k$:codebook $\mathcal{C}_0$ 中的第 $k$ 个向量
- $K$:codebook 大小(本文 $K=256$)
- $\arg\min$:找使距离最小的索引 $k$
直觉:在第一层 codebook 里找和当前残差最近的向量,记录它的索引作为第一个语义 token。
第 $d=1$ 层:计算残差 $\mathbf{r}_1 := \mathbf{r}_0 - \mathbf{e}_{c_0}$,再重复上述过程找 $c_1$。依此类推,重复 $m$ 次得到 Semantic ID $(c_0, c_1, \ldots, c_{m-1})$。
训练 RQ-VAE 的损失:
$$ \mathcal{L}_{RQVAE}(\mathbf{x}) = \mathcal{L}_{recon} + \mathcal{L}_{rqvae} $$- $\mathcal{L}_{recon} = \|\mathbf{x} - \hat{\mathbf{x}}\|^2$:重建损失,让解码器输出尽量还原原始 embedding $\mathbf{x}$
- $\hat{\mathbf{x}}$:解码器以量化表示 $\hat{\mathbf{z}} = \sum_{d=0}^{m-1} \mathbf{e}_{c_d}$ 为输入,还原出的向量
- $\mathcal{L}_{rqvae} = \sum_{d=0}^{m-1} \bigl(\|\mathrm{sg}[\mathbf{r}_d] - \mathbf{e}_{c_d}\|^2 + \beta\|\mathbf{r}_d - \mathrm{sg}[\mathbf{e}_{c_d}]\|^2\bigr)$:量化损失
- $\mathrm{sg}[\cdot]$:stop-gradient 操作,阻断梯度流,使 codebook 向量和编码器分别独立收敛
- $\beta$:平衡两个量化方向的超参数,论文取 $\beta = 0.25$
第一项让 codebook 向量往残差方向移动;第二项(带 $\beta$)让编码器输出往 codebook 向量移动,两者相互靠拢,但各自独立更新。
碰撞处理
当 codebook 大小和序列长度不足以区分所有 item 时,多个 item 可能映射到同一 Semantic ID(碰撞)。处理方式:在相同 $(c_0, c_1, c_2)$ 的 item 后面追加一个区分码,变成 $(c_0, c_1, c_2, 0)$、$(c_0, c_1, c_2, 1)$……保证唯一性。
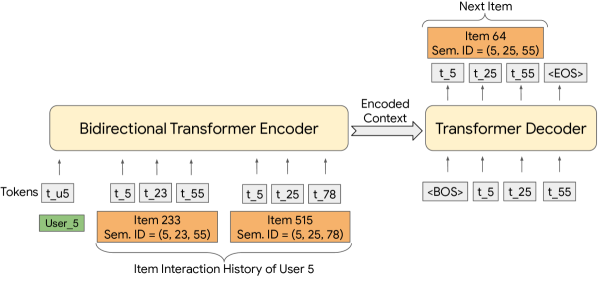
阶段二:生成式检索
把用户历史 item 序列转换为 Semantic ID 序列,训练一个 Encoder-Decoder Transformer(基于 T5X)做 Seq2Seq:
- 输入(Encoder):用户 ID token + 历史 item 的 Semantic ID 序列(展开为连续 token)
- 目标(Decoder):下一个 item 的 Semantic ID
训练目标(标准 next-token prediction):
$$ \mathcal{L}_{TIGER} = -\sum_{j=0}^{m-1} \log P\bigl(c_{n+1,j} \mid c_{n+1,0},\ldots,c_{n+1,j-1},\; \text{context};\;\theta\bigr) $$- $c_{n+1,j}$:第 $n+1$ 个(即下一个)item 的 Semantic ID 中第 $j$ 位 codeword
- $c_{n+1,0},\ldots,c_{n+1,j-1}$:已生成的前 $j$ 位(自回归条件)
- $\text{context}$:Encoder 编码的用户历史信息(用户 ID + 前 $n$ 个 item 的 Semantic ID 序列)
- $\theta$:Transformer Encoder-Decoder 的参数
- $m$:Semantic ID 长度(本文 $m=4$,前 3 位来自 RQ-VAE,第 4 位用于去碰撞)
这是标准的自回归语言模型目标,只不过生成的不是文字 token,而是 item 的 Semantic ID。Decoder 一次生成一个 codeword,生成完整 $(c_0, c_1, c_2, c_3)$ 后查表得到对应 item。
实验结果
主实验:TIGER vs SOTA 基线
在 Amazon 三个数据集(Beauty / Sports and Outdoors / Toys and Games)上与 GRU4Rec、SASRec、BERT4Rec、S3-Rec、P5 等对比:
| 数据集 | 最强基线 | TIGER Recall@5 | TIGER NDCG@5 | vs 最强基线 |
|---|---|---|---|---|
| Beauty | S3-Rec (R@5=0.0387) | 0.0454 | 0.0321 | +17.3% (Recall), +29% (NDCG) |
| Sports & Outdoors | S3-Rec (R@5=0.0251) | 0.0264 | 0.0181 | +5.2% (Recall), +12.6% (NDCG) |
| Toys & Games | SASRec (R@5=0.0463) | 0.0521 | 0.0371 | +12.5% (Recall), +21.2% (NDCG) |
消融实验:ID 类型对比
| ID 类型 | Beauty Recall@5 | Beauty NDCG@5 |
|---|---|---|
| Random ID | 0.0296 | 0.0205 |
| LSH Semantic ID | 0.0379 | 0.0259 |
| RQ-VAE Semantic ID | 0.0454 | 0.0321 |
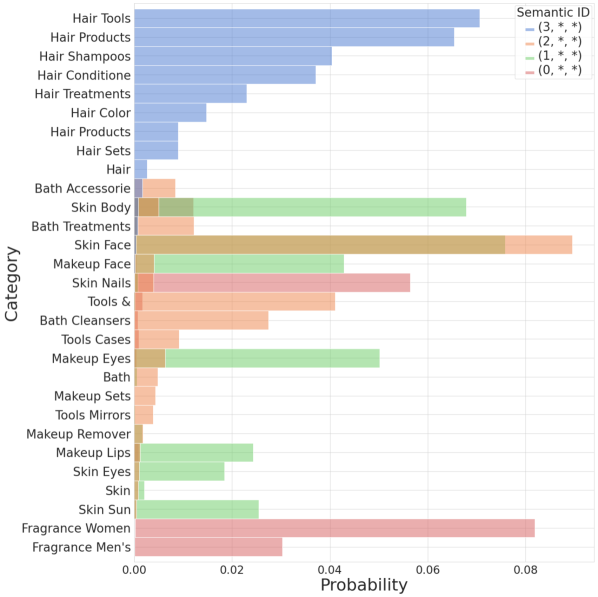
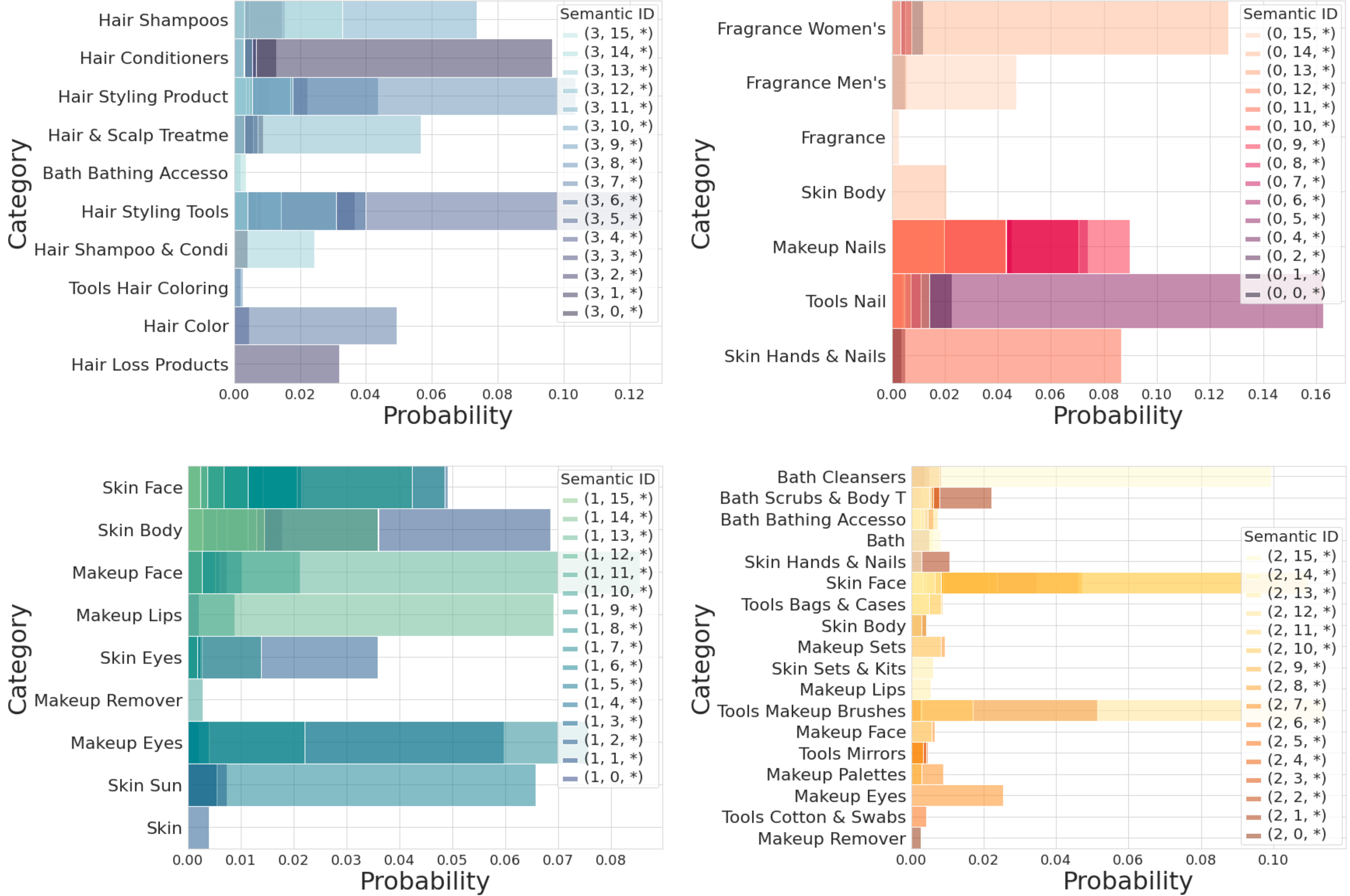
Semantic ID 层级质量分析(Figure 4)
在 Amazon Beauty 数据集上,设置 RQ-VAE 为 3 层、codebook 大小为 4/16/256,可视化第一层 codeword $c_1$ 与品类的对应关系:
冷启动推荐(Figure 5)
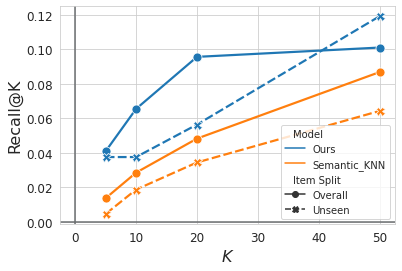
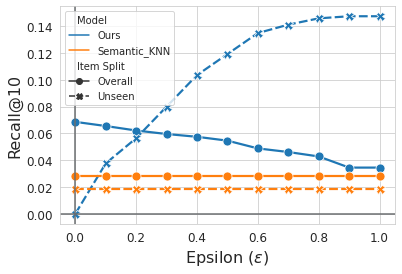
模拟新 item:从训练集移除 5% 的测试 item(unseen items),RQ-VAE 对这些 item 也能生成 Semantic ID(纯靠内容),TIGER 通过前缀共享把新 item 纳入候选集。引入超参数 $\epsilon$(最多 $\epsilon$ 比例的候选为新 item):
推荐多样性
通过调节 Decoder 的温度参数 $T$ 控制多样性。$T=1.0$ 时以精准为主,$T=2.0$ 时跨品类覆盖明显增大:
| 温度 T | Entropy@10 | Entropy@20 | Entropy@50 |
|---|---|---|---|
| T = 1.0 | 0.76 | 1.14 | 1.70 |
| T = 1.5 | 1.14 | 1.52 | 2.06 |
| T = 2.0 | 1.38 | 1.76 | 2.28 |
这是 ANN 难以做到的——ANN 只能通过后处理(如 MMR)做多样性,而 TIGER 可以在生成阶段通过温度采样在语义层级上控制多样性(高温时第一层 token 变化范围更大,直接跨品类)。
个人理解
TIGER 的真正创新点在哪里
- 把 Transformer 参数本身变成"索引":不需要单独的 embedding 表或 ANN 索引,模型推断时直接 beam search 出 Semantic ID 元组,再查表得 item。这在原理上消除了传统双塔的"离线索引 + 在线 ANN"两步走。
- Semantic ID 兼顾语义和层级:RQ-VAE 的残差量化天然产生粗粒度→细粒度的层级结构,既支持知识共享(相似 item 有共同前缀),又能区分个体(末位 codeword 唯一化)。
- 冷启动和多样性是自然涌现的能力:不需要专门设计冷启动模块,只是 Semantic ID 的前缀共享机制的副产物。
值得注意的局限
工业规模挑战
论文只在 1-2 万 item 的学术数据集上验证。工业场景 item 数亿,beam search 生成 Semantic ID 的延迟和 invalid ID 率是真实挑战。
只依赖内容特征
Semantic ID 完全来自内容 embedding,协同过滤信号没有进入 token 化过程,在行为驱动明显的场景可能次优。(SemID / TRM 论文正是解决了这个问题。)
碰撞处理有点粗糙
第 4 位只是顺序编号,没有语义含义,导致相似 item 的最后一位 token 完全无关,可能影响模型对末位 token 的学习。
RQ-VAE 需单独训练
两阶段训练(先 RQ-VAE,再 Seq2Seq)导致两个目标可能不完全一致,联合优化是后续工作的研究方向。
核心 takeaway:TIGER 的意义不只在于涨点,而在于提出了一个新的推荐系统范式:把 item 库"编码进" Transformer,用生成方式代替检索。这套思路在 LLM 时代有很强的延展性——SemID 把它用于排序,TRM 进一步引入协同信号和记忆 token。