Prefix-Ngram SID 用 RQ-VAE 为广告生成层次化语义 ID($L=6$ 层,$K=2048$),通过 Prefix-Ngram 展开(本质是笛卡尔积交叉特征)实现语义相近广告的 embedding 参数共享;高阶组合 modulo hash 到 50M 桶,利用「语义碰撞优于随机碰撞」的特性保持表示质量。在不增加 serving cost 的前提下,在 Meta 广告排序系统上实现在线 +0.15% 的核心指标提升、预测方差降低 43%,尾部广告和冷启动广告收益尤其显著。
论文:Semantic IDs for Large-Scale Recommendation Systems
机构:Meta(Facebook 广告排序系统)
状态:已在 Meta 广告排序系统生产部署超过 1 年
1.1 工业推荐系统中 ID 建模的三大困境
工业级推荐系统的核心是用 embedding 表示 item 的"身份",传统方案给每个 item 分配随机哈希 ID,查询一张巨大的嵌入表。在 Meta 广告系统亿级物品规模下暴露出三个根本性缺陷:
困境 1:高基数性
广告数量极大,远超可实用的嵌入表大小。哈希压缩导致不同广告被迫共用同一个嵌入向量,产生严重的哈希碰撞,模型无法区分语义不同的广告。
困境 2:展示偏斜
流量分布极度不均衡:0.1% 的头部广告贡献了 25% 的展示量,大量尾部广告几乎没有历史数据,模型泛化能力极差。
困境 3:ID 漂移
约一半广告在 6 天内退出系统,同时大量新广告涌入。随机哈希 ID 无法在新老广告之间传递任何知识,新广告冷启动困难。
根本原因:随机哈希 ID 是孤立符号
两个语义相似广告("耐克红色跑步鞋"和"耐克蓝色跑步鞋")的 ID 在数值上毫无关联,模型无法从中学到任何可迁移知识。


1.2 核心思路:让语义相似的广告共享嵌入知识
解题思路:用内容模型把广告多模态内容压缩成向量,再用层次化量化把向量映射成一串离散 token(Semantic ID),使语义相似广告自然拥有相同的前缀 token,从而实现 embedding 参数共享。
Prefix-Ngram SID 完整流水线
(文本+图像+视频)
内容嵌入 $\mathbf{e} \in \mathbb{R}^d$
SID $= (c_1,\ldots,c_L)$
$L$ 个前缀元组
→ 求和 → 接入 DLRM
2.1 内容嵌入提取
广告的语义内容来自多模态:文案标题、图片视觉、视频内容、落地页文本等。Meta 用专门的内容理解模型将这些信号融合为统一稠密嵌入向量 $\mathbf{e} \in \mathbb{R}^d$。
- 内容嵌入是离线预计算的,不参与排序模型的在线推理
- 内容模型独立训练,通常使用图文对比学习(CLIP 风格)或 LLM 文本表示
- 广告更新时重新计算内容嵌入,排序模型在线推理时直接查 SID 对应嵌入表
假设有三条广告:
- 广告 A:"Nike Air Max 跑步鞋 男款 红色"
- 广告 B:"Nike Air Max 跑步鞋 男款 蓝色"
- 广告 C:"女士高跟鞋 细跟 黑色"
经过内容理解模型,$\mathbf{e}_A$ 和 $\mathbf{e}_B$ 在空间中非常接近(余弦相似度 $\approx 0.95$),而 $\mathbf{e}_A$ 和 $\mathbf{e}_C$ 距离很远(余弦相似度 $\approx 0.3$)。这种语义近似性是 Prefix-Ngram 能共享 embedding 的基础。
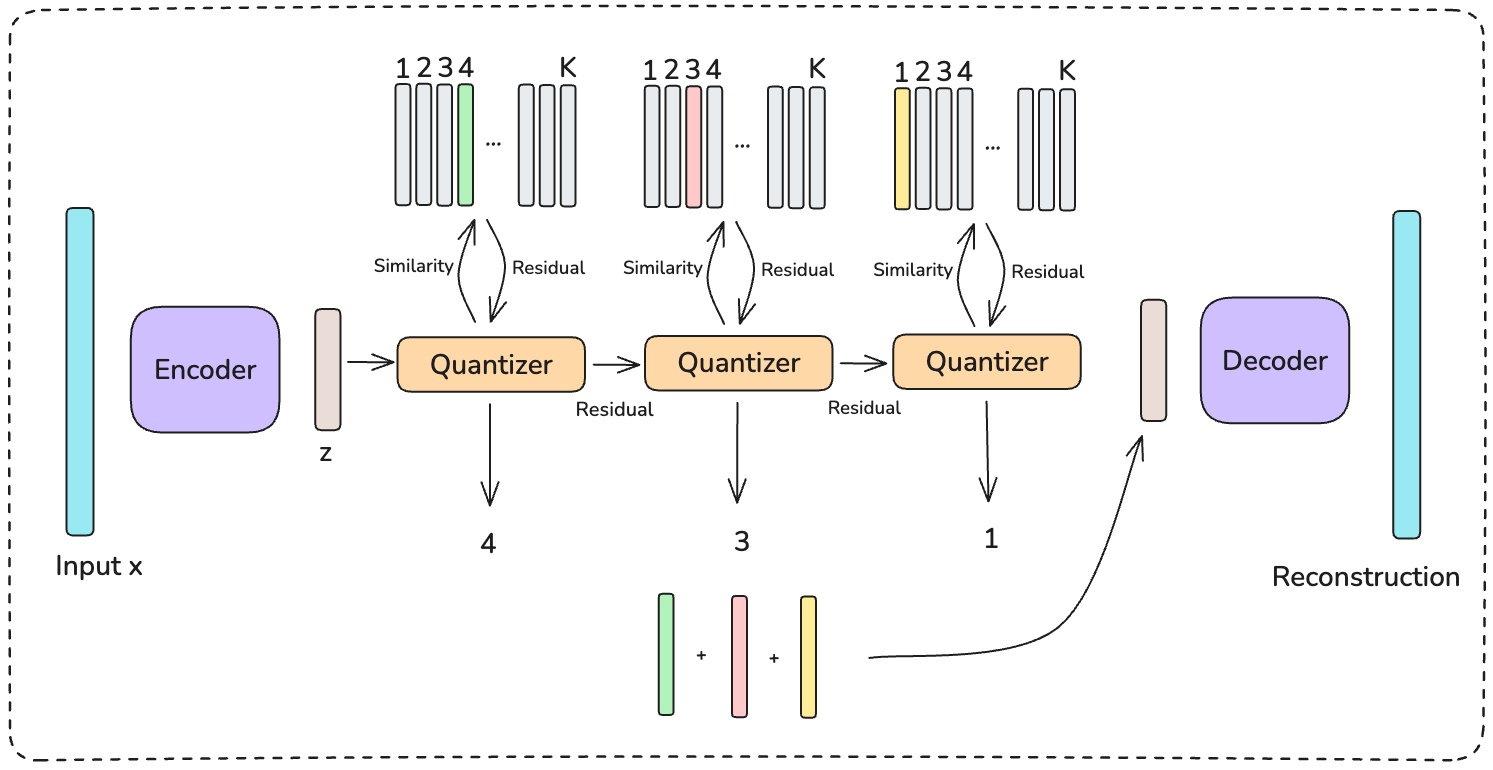
2.2 RQ-VAE 残差量化:生成层次化 SID
RQ-VAE(Residual Quantized VAE)用 $L$ 层 codebook 逐步逼近输入向量,每层量化上一层的"残差",最终用 $L$ 个离散 code 表示原始向量。
第 $l$ 层量化步骤:在 codebook $\{\mathbf{e}_k^{(l)}\}_{k=1}^{K}$ 中找最近邻:
- $\mathbf{r}_0 = \mathbf{e}$:初始残差为内容嵌入本身
- $\mathbf{r}_l$:第 $l$ 层量化后的残差,代表"还未被捕获的信息",模长随层数增加而减小
- $K = 2048$:每层 codebook 大小;$L = 6$:总层数
- $c_l \in \{1,\ldots,K\}$:第 $l$ 层分配到的 code 索引(整数)
- $\mathbf{e}_{c_l}^{(l)}$:第 $l$ 层第 $c_l$ 个码向量,从 $\mathbf{r}_{l-1}$ 中减去后得到更细的残差
最终输出 SID $= (c_1, c_2, \ldots, c_6)$,一个由 6 个整数组成的层次化 code 序列。越靠前的层代表越粗的语义粒度(大类),越靠后越细(细节差异)。
以 $L=3$(简化)为例,假设内容嵌入 $\mathbf{e} = [0.8, 0.6, 0.3]$:
- 第 1 层:在 codebook 1 中找最近邻,得 $c_1 = 47$(对应大类"运动鞋")。码向量 $\mathbf{e}_{47}^{(1)} = [0.7, 0.5, 0.2]$,残差 $\mathbf{r}_1 = [0.1, 0.1, 0.1]$
- 第 2 层:量化残差 $\mathbf{r}_1$,得 $c_2 = 132$(对应中类"耐克跑步鞋"),残差缩小至 $\mathbf{r}_2 \approx [0.02, 0.01, -0.01]$
- 第 3 层:量化极小残差,得 $c_3 = 8$(对应细节"颜色差异")
最终 SID = (47, 132, 8)。广告 B(蓝色版)可能得到 SID = (47, 132, 15)——前两层完全相同,只在第 3 层不同。正是这个层次性使得 Prefix-Ngram 能实现知识共享。
2.3 Prefix-Ngram 特征构造:本质是笛卡尔积交叉特征
三个方案的对比:从简单到复杂
理解 Prefix-Ngram 的最好方式是先搞清楚它和两种更简单方案的区别:
| 方案 | 具体做法 | $c_1=47$ 查的 key | $c_2=132$ 查的 key | 有 $c_1 \times c_2$ 的交叉嵌入? | 表的大小 |
|---|---|---|---|---|---|
| 随机哈希 ID | 每个广告分配一个随机 ID,直接查一张大表 | 广告 ID → 一行 embedding(数十亿行) | ——(整个广告是一个 key) | 数十亿行 | |
| Per-slot unigram (各层独立查表) |
$c_1$ 查第 1 张表,$c_2$ 查第 2 张表……各自独立,结果求和 | $(47)$ → 2048 行表的第 47 行 | $(132)$ → 2048 行表的第 132 行 | ❌ 无($c_1$ 和 $c_2$ 完全独立) | $L \times 2048 = 12288$ 行 |
| Prefix-Ngram (本文方案) |
$l$-gram 表的 key 是前 $l$ 层 code 的组合元组,所有层求和 | $(47)$ → 2048 行 1-gram 表 | $(47,\mathbf{132})$ → ~4M 行 2-gram 表 | ✅ 有:$(47,132)$ 是一个独立的 key | ~50M 行(哈希压缩) |
推荐里「用户城市 × 商品类目」这种二阶交叉特征,是把两个 slot 的值拼起来 $(city, category)$ 查一张交叉表。Prefix-Ngram 的 2-gram 做的完全一样:$(c_1, c_2)$ 就是第 1 层和第 2 层 code 的笛卡尔积,查一张专属的 2-gram 嵌入表。
区别只是推荐里的 slot 是原始特征值,而这里的 slot 是 RQ-VAE 量化出来的语义 code。
表的大小:为什么不是 $2048^5$?
$l$-gram 表的理论行数是 $2048^l$:
- 1-gram:$2048^1 = 2048$ 行 — 直接存,没问题
- 2-gram:$2048^2 \approx 4\text{M}$ 行 — 还可以接受,论文直接存
- 3-gram:$2048^3 \approx 8.6\text{B}$ 行 — 太大,哈希到约 50M 桶
- 4-gram、5-gram:更大,同样哈希到约 50M 桶
3-gram 及以上都哈希到同一个约 50M 行的桶里(不同层各自独立的 50M 桶),多个不同的 $(c_1,c_2,c_3)$ 组合可能映射到同一桶(哈希碰撞),这和推荐里用哈希桶压缩高阶交叉特征是完全相同的工程取舍。总参数量约 50M,远小于随机哈希 item ID 表的数十亿行。
「交叉嵌入」相比 per-slot 真正多出来的是什么?
一个重要的澄清:per-slot unigram 方案里,广告 B 的冷启动问题已经部分被解决了——因为 $c_1=47$、$c_2=132$ 都被其他广告训练过,广告 B 上线时这些 slot 的嵌入不是随机的。那 Prefix-Ngram 真正多出来的贡献是什么?
答案是:显式编码了各层 code 之间的交互语义(interaction)。
考虑两类广告,它们的 $c_1=47$(运动用品)完全相同,$c_2$ 不同:
- 广告组 X:$c_1=47, c_2=\mathbf{132}$(跑步鞋)
- 广告组 Y:$c_1=47, c_2=\mathbf{201}$(健身器材)
Per-slot 方案的嵌入:
v_X = e_1[47] + e_2[132] v_Y = e_1[47] + e_2[201]
$c_1=47$ 的嵌入 $e_1[47]$ 必须同时对跑步鞋用户和健身器材用户「有用」,它只能学到「运动用品」这个粗粒度的信息。$c_2$ 的 unigram 嵌入学到的是「跑步鞋在任意类目语境下的含义」,不区分它属于哪个父类。
Prefix-Ngram 方案的嵌入:
v_X = e_1gram[47] + e_2gram[(47,132)] + ... v_Y = e_1gram[47] + e_2gram[(47,201)] + ...
2-gram 的 $(47,132)$ 是一个独立 key,它的嵌入可以专门学「运动用品类目下跑步鞋的用户偏好」,不和健身器材混在一起。模型不需要通过 MLP 隐式学习这种交互,特征层就已经把「父类 × 子类」的组合信息显式编码了。
这和推荐里「直接用笛卡尔积特征(显式交叉)」vs「用 FM/DNN 让网络隐式学交叉」的区别是完全一样的道理。
完整公式
- $\text{Lookup}_l(\cdot)$:第 $l$ 个嵌入表,key 是前 $l$ 层 code 的组合元组(= $l$-gram)
- 1-gram 表:2048 行;2-gram 表:~4M 行;3-gram 以上各自哈希到 ~50M 行
- 求和(sum pooling):输出维度固定为 $d$,不随层数增加,对下游模型透明
广告 A(耐克红色跑步鞋,大量曝光):SID = $(47, 132, 8, 5, 21, 3)$
广告 B(耐克蓝色跑步鞋,刚上线):SID = $(47, 132, 8, 5, 9, 1)$
| gram 级别 | 广告 A 的 key | 广告 B 的 key | 是否共享同一行嵌入 |
|---|---|---|---|
| 1-gram(类目) | $(47)$ | $(47)$ | ✅ 完全共享 |
| 2-gram(类目×子类) | $(47,132)$ | $(47,132)$ | ✅ 完全共享 |
| 3-gram(类×子×品牌) | $(47,132,8)$ | $(47,132,8)$ | ✅ 完全共享 |
| 4-gram(+系列) | $(47,132,8,5)$ | $(47,132,8,5)$ | ✅ 完全共享 |
| 5-gram(+颜色) | $(47,132,8,5,21)$ | $(47,132,8,5,9)$ | ❌ 不同(红 vs 蓝) |
| 6-gram(完整款式) | $(47,...,3)$ | $(47,...,1)$ | ❌ 不同 |
广告 B 上线时,前 4 层的交叉嵌入($(47)$、$(47,132)$、$(47,132,8)$、$(47,132,8,5)$)都已经被广告 A 训练充分,只有 5-gram 和 6-gram 嵌入从随机初始化开始。这既有 per-slot 里 $c_1, c_2$ 被训练到的好处,也额外有「运动用品×跑步鞋×耐克×React」这个 4 层交叉组合的专属嵌入已经学好的收益。
- Concat:输出维度 $= L \times d$,下游 MLP 第一层参数量 $L$ 倍增,排序模型要改架构
- Sum pooling:输出维度固定 $= d$,对现有排序模型零侵入,直接替换原来的 item embedding 即可
- 代价:不同粒度嵌入加在一起,粗粒度嵌入的梯度信号会被细粒度嵌入稀释(LiGR 论文后来改成 concat,效果更好但工程成本更高)
2.4 RQ-VAE 训练 loss 与哈希碰撞的处理
RQ-VAE 的训练 loss(论文原文,仅两项)
论文 Section 4.1 给出的 RQ-VAE loss 只有两项,没有额外的正则项:
- $\mathbf{r}_l = \mathbf{z} - \sum_{i=1}^{l-1}\mathbf{v}_{c_i}^i$:第 $l$ 层的残差向量(上一层量化后剩余的误差)
- $\mathbf{v}_{c_l}^l$:第 $l$ 层 codebook 中,code $c_l$ 对应的向量
- $\text{sg}(\cdot)$:stop-gradient,阻止梯度流过该项
- 第一个 commitment 项:固定 codebook,让 encoder 输出的残差靠近 code 向量(更新 encoder)
- 第二个 commitment 项:固定 encoder,让 code 向量靠近残差(更新 codebook,即 EMA 更新)
- $\beta = 0.5$(论文设定值)
之前的版本里写了「FLOPs 正则化防 codebook collapse」,这是错误的——这个概念来自 Switch Transformer 等 MoE 论文,本论文完全没有使用 FLOPs 正则化。论文的 RQ-VAE loss 只有上面的两项,没有均匀性约束。
高阶 ngram 的哈希压缩:会不会撞太多?
3-gram 及以上的理论组合数是 $2048^3 \approx 8.6\text{B}$,远超可存储的嵌入表大小,所以论文用 modulo hash 压缩到约 50M 桶(Section 4.2):
index = hash((c1, c2, ..., cl)) % H # H ≈ 50M
同时为了防止不同层的相同 index 映射到同一行(比如 2-gram 的 index 5 和 3-gram 的 index 5 碰撞),论文加了 shifting factor:
index_l = (hash((c1,...,cl)) % H) + shift_l # 每层 shift 不同
这里需要区分两件不同的事,论文把它们混在一起说了,容易误解:
- 事情一(不是碰撞,是设计):相同 SID 前缀 → 必然查同一行
广告 A 和 B 的 3-gram 前缀 $(c_1,c_2,c_3)$ 完全一样,hash 同一个 tuple 自然得到相同 index。这两个广告确实语义相近——因为 SID 是 RQ-VAE 从内容嵌入学到的,相同前缀 = 落入同一内容聚类 = 内容相近。这是 Prefix-Ngram 的核心设计,不是碰撞。 - 事情二(真正的 hash 碰撞):不同 SID 前缀 → 偶然 hash 到同一行
$(47,132,8)$ 和 $(51,77,203)$ 是两个完全不同的前缀,modulo hash 后恰好落到同一桶。这两个广告的语义不一定相近——和随机哈希的碰撞本质上没有区别,只是发生的概率更低(因为 tuple 空间更大,碰撞因子约为 3)。
论文 Abstract 里说的「semantically meaningful collisions」指的是事情一(相同 SID 前缀共享),而不是说 modulo hash 本身会产生语义相关的碰撞。用「碰撞」来描述事情一本就不太准确。真正的 hash 碰撞(事情二)仍然是随机的,只是因为 3-gram 的 tuple 空间是 $2048^3 \approx 8.6\text{B}$,压缩到 50M 桶后碰撞因子约为 170,所以两个随机广告碰到同一桶的概率比随机哈希小得多。
简单总结哈希压缩对质量的实际影响:
- 相同 SID 前缀的广告:共享同一行 embedding → 完全有意的语义知识共享,是设计目标
- 不同 SID 前缀但 hash 后撞到同一行的广告:梯度互相干扰 → 仍然是噪声,但发生概率比随机哈希低(tuple 空间更大)
- 整体效果为何仍然更好:大多数广告对之间的 SID 前缀不同,也不会 hash 碰撞;而 Prefix-Ngram 通过「相同前缀共享」带来了随机哈希完全没有的知识迁移收益,净效果是正的
实验里 RH 和 SemID 都设置了 collision factor = 3(平均每桶 3 个广告),控制了「参数量相同」这个变量,只比较「随机碰撞 vs SemID 方案」的效果差异。结果 SemID 更好,说明 SemID 的收益不只来自参数量节省,而是来自「相同 SID 前缀共享 embedding」带来的知识迁移,尤其对尾部广告和冷启动广告帮助最大。
2.5 SemID 如何接入排序模型
模型整体结构(Section 3)
论文使用 Meta 内部的 DLRM 风格排序模型,分三层:
- 信息聚合层:sparse feature(离散特征)、dense feature(连续特征)、用户历史序列 feature 各自独立处理,输出一组 embedding 向量
- 交互层:对所有向量两两做点积(或高阶交互)
- MLP 层:把交互结果经 MLP 输出 logit,sigmoid 得到 CTR 预估概率
SemID 特征作用于第 1 层,分别进入 sparse feature 模块(目标候选广告)和用户历史序列模块。
用法一:目标候选广告的 Sparse Feature(新增,不替换)
对被打分的目标广告,取其 SID,做 Prefix-Ngram 展开,查嵌入表,sum pooling 得到 $\mathbf{v}_\text{item}$,作为一个新增的 sparse feature 进入 sparse 模块。原有的随机哈希 ID 特征保留,SemID 是在它旁边新加一列。
「We created six sparse and one sequential feature from different content embedding sources, including text, image, and video.」
6 个 sparse feature = 来自文字、图片、视频等不同内容模型各自训练的 RQ-VAE 生成的 SemID Prefix-Ngram 嵌入,都新增进 sparse 模块。
用法二:用户历史序列模块(Section 6.4)
用户历史序列 $\mathbf{x}^u = (x_1^u, \ldots, x_T^u)$ 中每个历史交互广告,也各自用 SemID Prefix-Ngram 生成嵌入,替换原来的随机哈希 ID 嵌入,再送入序列聚合模块做上下文建模。论文对比了三种聚合模块:
| 聚合模块 | 做什么 | SemID 的额外收益 |
|---|---|---|
| Bypass | 对每个历史 item embedding 各自乘一个线性矩阵 $\mathbf{W}$,不做序列交互:$\text{Bypass}(\mathbf{X}) = \mathbf{X}\mathbf{W}$ | 较小(SemID 提升了单个 item 的 embedding 质量,但没有跨 item 的语义交互) |
| Transformer | 标准 Multi-Head Self-Attention,每个位置的 item 和所有其他位置的 item 做 attention,捕捉序列内的 item 间关系 | 较大(SemID 让语义相近的历史 item 嵌入更接近,attention 能准确识别语义相关的历史行为) |
| PMA(Pooled Multi-head Attention) | 见下方说明 | 最大 |
PMA(Pooled Multi-head Attention)是什么?
PMA 来自论文 Set Transformer(Lee et al., 2019),目的是把一个变长序列压缩成固定长度的表示,同时利用 attention 机制筛选出有价值的历史 item。
论文附录 A 给出了完整定义:
- $\mathbf{X} \in \mathbb{R}^{T \times d_m}$:用户历史序列,$T$ 个 item 各自的 embedding
- $k$:压缩目标长度(输出 $k$ 个向量,$k \ll T$,论文设 $k=32$)
- $\mathbf{S} \in \mathbb{R}^{k \times d_m}$:$k$ 个可学习的「查询向量」(seed vectors),随机初始化后随模型训练
- $\text{MAB}(\mathbf{X}, \mathbf{X})$:先对序列自身做一次 Multi-head Attention(类似 Transformer 的一层)
- $\text{MultiHeadAttn}(\mathbf{S}, \cdot)$:用 $k$ 个 seed 向量作为 Query,对上一步的输出做 Cross-Attention,得到 $k$ 个压缩后的向量
假设用户历史有 $T=500$ 条交互记录,但下游 MLP 不希望处理一个 500×d 的矩阵(计算量太大)。PMA 的做法:
- 准备 $k=32$ 个可学习的「兴趣探针」向量 $\mathbf{S}$(可以理解为 32 种预设的兴趣模式)
- 用这 32 个探针对 500 条历史记录做 attention,每个探针「关注」和自己最相关的历史记录
- 输出 32 个向量,每个向量是某种兴趣模式在该用户历史上的提炼
为什么叠上 SemID 效果更好?用 RH 时,历史序列里跑步鞋 A 和跑步鞋 B 的 embedding 完全随机不相关,attention 看不出「这两个都是跑步鞋」。用 SemID 后,A 和 B 的前缀 SID 相同,embedding 相近,attention 能准确识别「用户历史里有多次跑步鞋相关行为」,兴趣探针的 attention 权重也更有语义意义,压缩结果更准确。
完整的特征接入流程(生产)
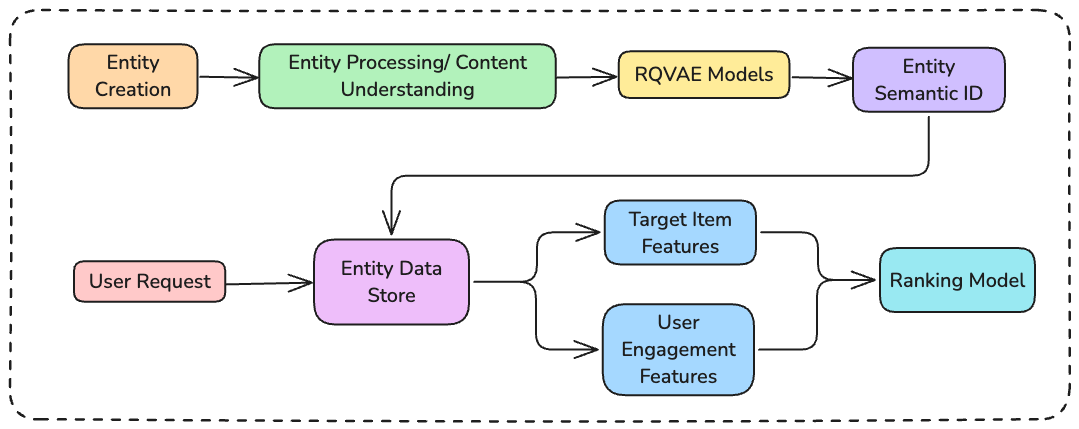
- 离线:RQ-VAE 训练——用过去 3 个月的广告内容嵌入训练 RQ-VAE,冻结 checkpoint
- 广告创建时:SID 生成——新广告内容经内容理解模型 → RQ-VAE → 得到 SID,存入 Entity Data Store
- 特征生成阶段:Prefix-Ngram 展开——目标广告和历史序列广告各自取出 SID,展开成前缀元组,查嵌入表
- 排序模型训练:端到端微调嵌入表——RQ-VAE 冻结,Prefix-Ngram 嵌入表随排序模型一起训练(CTR 信号端到端回传)
- 在线推理:serving cost 不增加——SID 已预计算,在线只需查表,和原来的 RH ID 查表一样快
3.1 离线实验:NE(Normalized Entropy)指标
论文使用 NE(Normalized Entropy,归一化交叉熵,越低越好,对应越好的预测质量)作为主要离线指标。
| 实验组 | NE 变化 | 说明 |
|---|---|---|
| 随机哈希 ID(基线) | 0 | 传统方案 |
| SID(无 Prefix-Ngram) | -0.12% | SID 本身有提升 |
| SID + Prefix-Ngram(Prefix-5gram) | -0.28% | Prefix-Ngram 进一步提升 |
| 尾部广告子集 NE | -0.41% | 长尾广告收益更大 |
| 新广告(冷启动)子集 NE | -0.33% | 冷启动显著改善 |
3.2 前缀深度 vs. 点击损失率
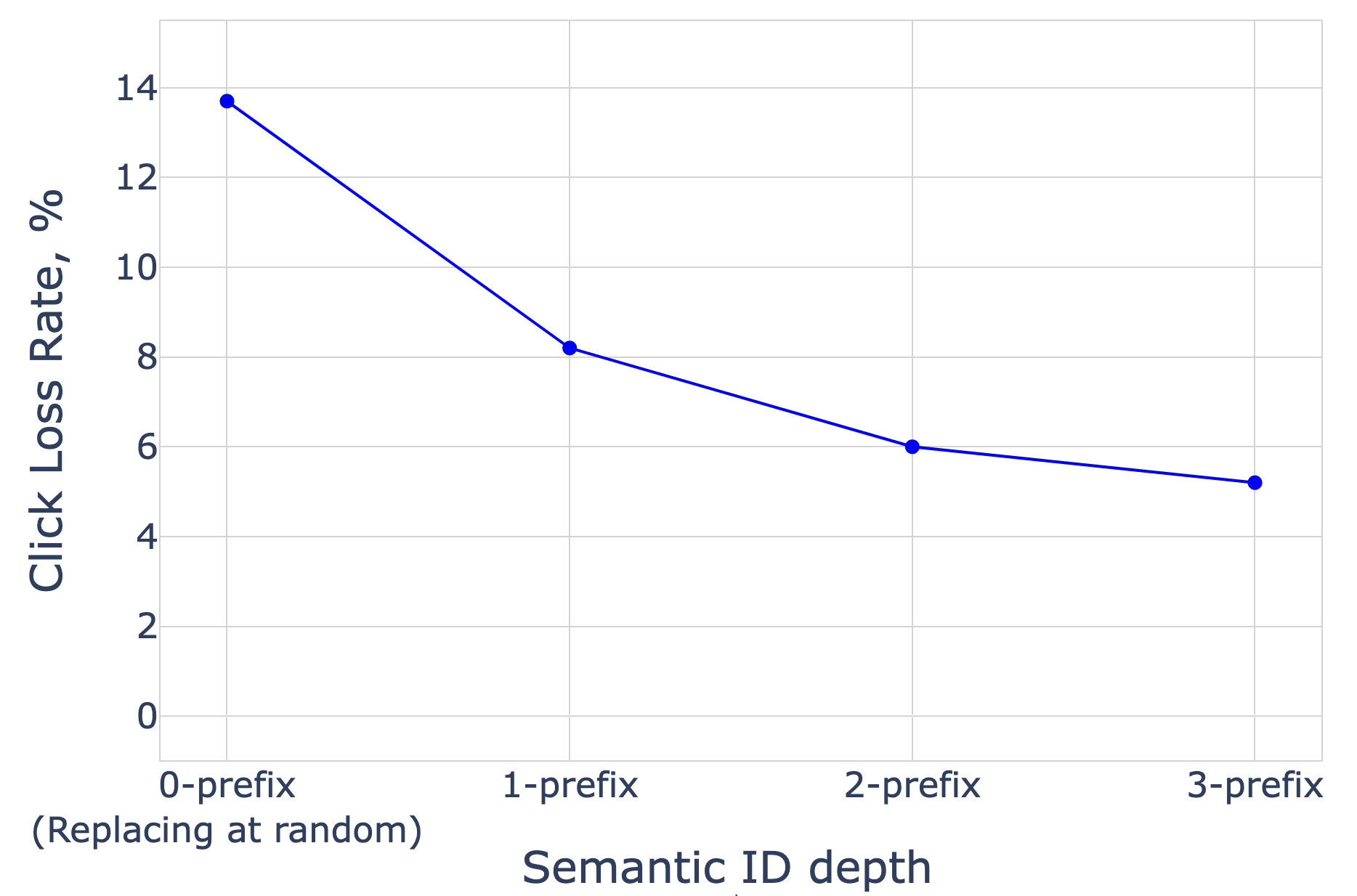
点击损失率随前缀深度增加单调下降,验证了层次化特征的有效性。本文最终选择 Prefix-5gram(即 $l = 1 \sim 5$)作为生产配置。
3.3 SID 分布可视化:语义聚类效果
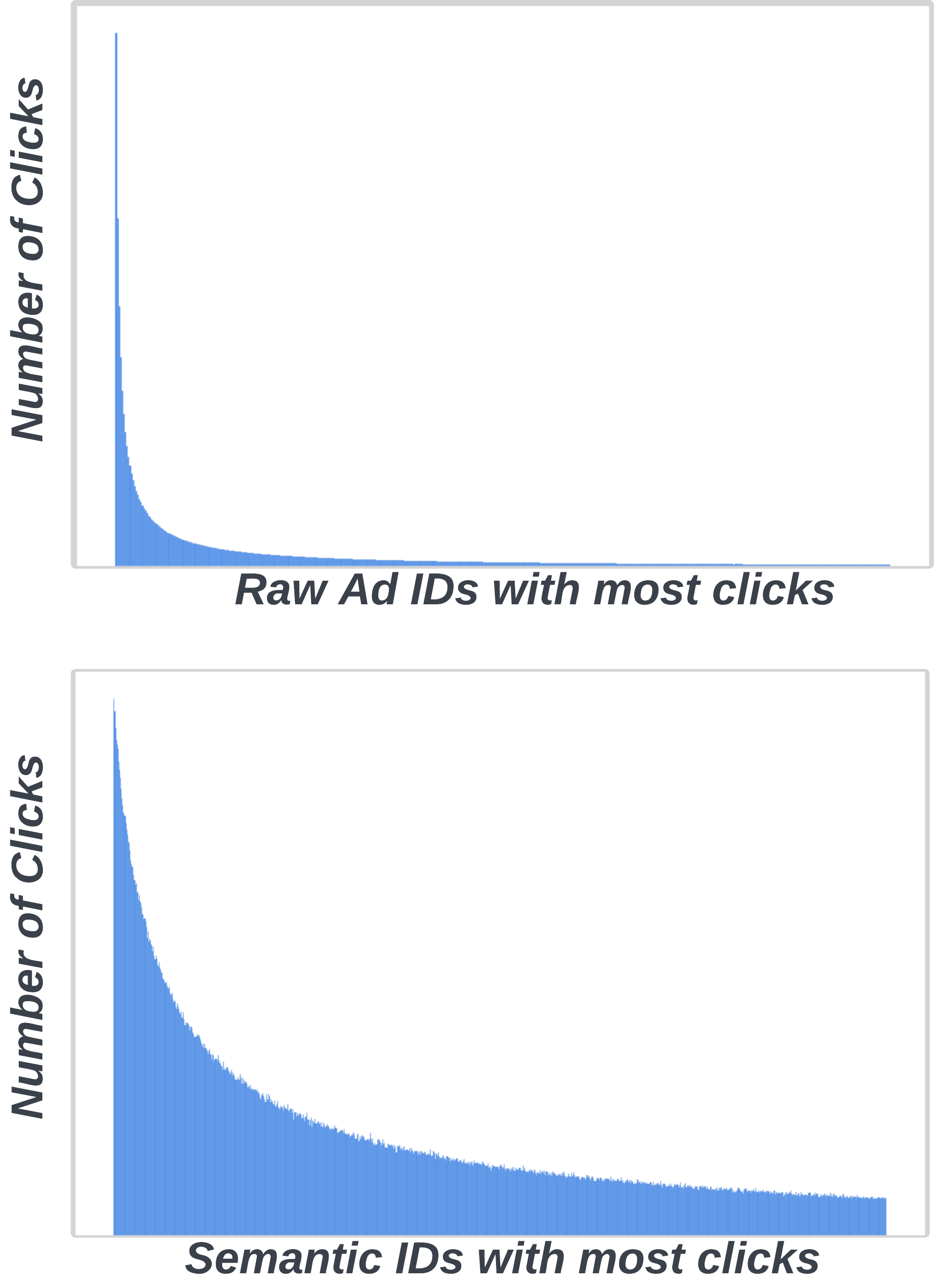
3.4 在线 A/B 测试(生产环境)
- 在线核心指标提升:+0.15%(统计显著)
- A/A 预测方差降低:43%——说明 SID embedding 比随机哈希 ID 更稳定,预测结果的随机波动显著减小
- 注意力机制模块(如 Target Attention)叠加 SID 后收益显著放大
- 20 天长期训练后,SID 方案的性能扩展性明显优于随机哈希 ID
3.5 超参数分析
| 超参数 | 最优值 | 说明 |
|---|---|---|
| codebook 层数 $L$ | 6 | 更多层能捕获更细粒度细节,但收益递减 |
| 每层 codebook 大小 $K$ | 2048 | $K=256$ 时 code 利用率高但表达能力差;$K=4096$ 时 collapse 风险增大 |
| Prefix 深度 | 5-gram | 1~5 gram 单调改善,5-gram 是生产配置 |
| 总 embedding 参数量 $H$ | $\sim$50M | 与随机哈希 ID 方案持平,serving cost 不增加 |
Prefix-Ngram SID 用 RQ-VAE 为广告生成层次化语义 ID($L=6$ 层,$K=2048$),通过 Prefix-Ngram 展开(本质是笛卡尔积交叉特征)实现语义相近广告的 embedding 参数共享;高阶 ngram 用 modulo hash 压缩到 50M 行,产生「语义碰撞」(比随机碰撞更优)。在不增加 serving cost 的前提下,在 Meta 广告排序系统上实现在线 +0.15% 的核心指标提升、预测方差降低 43%,尾部广告和冷启动广告收益尤其显著。
核心贡献总结
✅ 主要亮点
- 高阶 ngram 的 modulo hash 压缩产生「语义碰撞」,比随机碰撞更优——这是论文的核心设计哲学之一
- Prefix-Ngram 展开天然实现粗细粒度的层次化知识共享
- serving cost 不增加(总参数量 $H \approx 50\text{M}$,与随机哈希 ID 持平)
- 方差降低 43%,提升实验可信度,对广告系统工程价值很高
- 生产部署 1 年+,稳定性有充分验证
⚠️ 局限与注意
- 内容嵌入质量决定 SID 质量上限,内容模型需要独立维护
- SID 生成是离线的,对于极其频繁更新的广告(分钟级),存在内容-SID 不同步问题
- RQ-VAE 训练本身有成本,需要额外的离线流水线
- 论文发表时主要是广告场景,内容推荐(视频、图文)需要额外验证