LIGER 首先通过严格控制变量的实验,证明了在小规模学术 benchmark 上生成式检索(TIGER)全面落后于稠密检索,并揭示了冷启动物品几乎无法被生成式模型检索到的根本原因;随后提出混合方案:用 Decoder 做 Beam Search 缩小候选集,补充冷启动物品,再用 Encoder 的稠密向量做最终排序,实现了两者的优势互补。
📄 原文:https://arxiv.org/abs/2411.18814
🔗 基础:TIGER(arXiv 2305.05065,NeurIPS 2023)—— RQ-VAE Semantic ID + 生成式召回
🔗 延伸:COBRA(arXiv 2503.02453)进一步把稠密向量融入生成过程
① 公平对比实验(相同输入+相同架构)证明:学术 benchmark 上生成式检索性能全面低于稠密检索,且对冷启动物品 Recall ≈ 0;
② 定量分析冷启动失效根因:模型生成冷启动物品的概率 $p^\star$ 始终低于 Beam Search 第 $K$ 名的阈值 $p_K$,物品永远进不了候选集;
③ 提出 LIGER 混合框架:Beam Search 粗召 $K$ 个候选 + 补充冷启动集 + 稠密精排,在所有数据集上达到最好或第二好的成绩。
稠密检索(Dense Retrieval)
序列推荐的主流做法:用 Transformer Encoder 对用户交互历史建模,输出一个稠密向量 $\hat{\mathbf{E}}$,然后与全量物品的 embedding 做内积搜索,取 Top-K 作为推荐结果。
✅ 优势
- 精度高,长期迭代优化成熟
- 支持冷启动(文本 embedding 提供先验信息)
- 训练目标明确(对比学习/内积优化)
⚠️ 不足
- 存储代价 $O(N)$:每个物品一个向量
- 推理要对比全量物品:$O(N)$ 计算
- 物品库增长时存储/计算线性增加
生成式检索(Generative Retrieval)
TIGER 提出的新范式:用 RQ-VAE 把每个物品的文本 embedding 量化成 $m$ 个整数(Semantic ID),然后训练 Encoder-Decoder Transformer 直接"生成"下一个物品的 Semantic ID 序列,用 Beam Search 解码出 Top-K 候选。
✅ 优势
- 存储只需 $O(t)$:只存 $t$ 个 codebook 向量
- 推理代价 $O(t \cdot K)$:Beam Search,远小于 $O(N)$
- 语义相似物品共享 Semantic ID 前缀
⚠️ 不足(本文揭示)
- 学术集上精度系统性低于稠密检索
- 冷启动物品生成概率近乎为零
- 预测机制(next-token prediction)效率低
性能差距:严格控制变量后的公平对比
以往很多论文在不同输入信息、不同架构下比较两者,结论可信度存疑。LIGER 严格控制:相同文本输入(Sentence-T5 XXL embedding)+ 相同 Transformer 架构(6 层 T5)+ 相同数据预处理,做了消融分析:
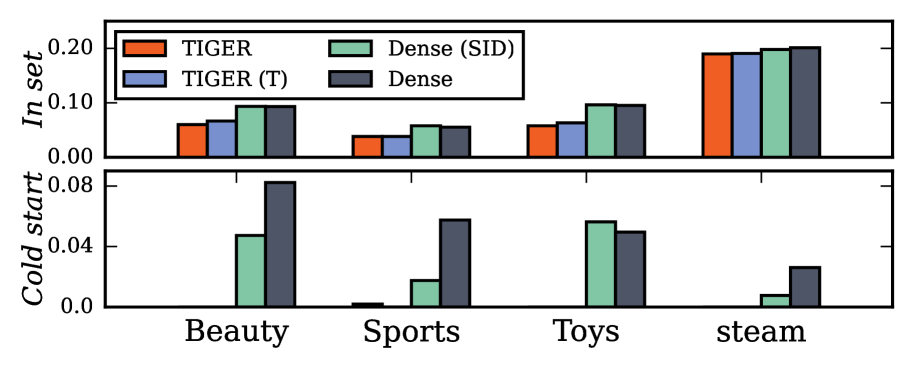
| 方法 | 输入信息 | 预测机制 | In-set 性能 | Cold-start 性能 |
|---|---|---|---|---|
| Dense (ID) | Item ID + 文本 emb | 内积搜索 | 中 | 中(文本提供先验) |
| Dense (SID) | Semantic ID + 文本 emb | 内积搜索 | 高(接近 Dense ID) | 中-高 |
| TIGER | Semantic ID(阶段2不用文本) | Beam Search 生成 | 低 | ≈ 0 |
| TIGER (T) | Semantic ID + 文本 emb | Beam Search 生成 | 稍高于 TIGER | ≈ 0 |
冷启动困境的量化分析
生成式检索对冷启动物品几乎失效。论文对此给出了精确的量化解释:
模型用 Beam Search 生成 $K$ 个候选,第 $K$ 名被选中的生成概率记为 $p_K$(这是进入候选集的最低门槛)。
冷启动物品的 Semantic ID 从未出现在训练集中,模型生成该 ID 序列的概率记为 $p^\star$。实验发现对于所有 $K \in \{10, 20, 40, 80\}$,$p^\star < p_K$ 始终成立。
$p_{\text{diff}} = p_K - p^\star > 0$ 的差值随 $K$ 增大而缩小,但始终大于 0。这意味着即使无限扩大 $K$,冷启动物品也难以自然进入候选集——除非使用显式补充机制。

训练阶段:模型在 Amazon Beauty 数据集训练,学到了"护肤品用户序列 → 下一个物品大概率是某类护肤品 Semantic ID"的分布。这个分布是在训练集物品的 ID 上拟合的。
冷启动物品:新上线的口红产品 X,其 Semantic ID = (12, 5, 8, 1)。这个序列在训练集的条件概率分布中出现概率极低(甚至为 0),因为模型从没见过"用户喜欢 X"这样的训练样本。
Beam Search 的问题:Beam Search 只保留生成概率最高的 K 个路径。训练集中 Top-1000 的常见物品生成概率很高($p_K$ 对应第 K 名),而 X 的概率 $p^\star$ 远低于这个门槛,永远进不了候选集。
对比稠密检索:稠密方法用物品的文本 embedding 作为先验,X 的文本 embedding("口红、持色、哑光")与用户历史中相似物品语义接近,能通过内积搜索被召回——这就是 Cold-start 场景下稠密方法非零而生成式方法为零的原因。
LIGER(LeverageIng dense retrieval for GEnerative Retrieval)的设计原则:用生成式检索压缩候选空间,用稠密向量精排,显式补充冷启动物品。
+ 物品位置 + SID 位置
Transformer
双头输出
Beam Search
$\mathcal{I}_{\text{beam}}$
输入 Embedding 构建
对用户历史中的每个物品 $i$(其 Semantic ID 为 $(s_i^1, s_i^2, \ldots, s_i^m)$),LIGER 为 Semantic ID 的每一位 $j$ 构建输入 Embedding:
- $\mathbf{E}_{s_i^j}$:物品 $i$ 的第 $j$ 个 Semantic ID 对应的输入向量,作为 Transformer 的 token 输入
- $\mathbf{e}_{s_i^j}$:第 $j$ 位 Semantic ID 值(整数)的可学习 embedding,来自共享码表
- $\mathbf{e}_i^{\text{text}}$:物品 $i$ 的文本 embedding,由 Sentence-T5 XXL 编码物品属性(标题/价格/类目/描述)得到,在 TIGER 阶段2中被丢弃,LIGER 全程保留
- $\mathbf{e}_i^{\text{pos}}$:物品 $i$ 在用户交互序列中的位置 embedding(第几个交互物品)
- $\mathbf{e}_j^{\text{pos}}$:Semantic ID 内部第 $j$ 位的位置 embedding(区分同一物品的不同 SID 位)
- 物品 $i$ 的完整输入:$\mathbf{E}_i = [\mathbf{E}_{s_i^1}, \mathbf{E}_{s_i^2}, \ldots, \mathbf{E}_{s_i^m}]$(拼接为序列)
TIGER 的做法:阶段2完全丢弃文本 embedding,只用可学习的 SID embedding $\mathbf{e}_{s_i^j}$。新物品的 SID 从来没在训练中出现过,对应的 embedding 是随机初始化,模型无法识别。
LIGER 的做法:每个 token 输入 = SID 可学习 embedding + 文本 embedding + 两个位置 embedding。文本 embedding 是用预训练语言模型从物品内容(标题、类目等)编码来的,新物品同样可以生成有意义的文本 embedding。
为什么还不够:即使 TIGER 加了文本 embedding(TIGER(T)),冷启动仍然失败——因为文本 embedding 只改善了输入端的语义,但 Decoder 的生成分布仍然只覆盖训练集物品的 SID。输入再好,生成出口没有冷启动物品的"路",也是徒劳。
双目标训练:稠密 Loss + 生成 Loss
LIGER 的 Transformer 是 Encoder-Decoder 架构,两个输出头同时训练:
联合训练目标
- $\hat{\mathbf{E}}(\Theta)$:Encoder 对输入序列 $\{E_1, \ldots, E_n\}$ 的输出向量("预测的用户表示")
- $\mathbf{e}_{n+1}^{\text{text}}$:下一个目标物品的文本 embedding(Sentence-T5 编码,固定不更新)
- $\text{sim}(\cdot, \cdot)$:余弦相似度
- $\tau$:温度超参数,越小对比越尖锐
- 第一项(稠密 Loss):Softmax 对比损失,让 Encoder 输出对齐下一物品的文本 embedding,实现稠密检索能力
- 第二项(生成 Loss):自回归逐 token 预测下一物品的 Semantic ID 序列 $(s_{n+1}^1, \ldots, s_{n+1}^m)$,赋予 Decoder 生成式检索能力
- $s_{n+1}^j$:目标物品 Semantic ID 的第 $j$ 位整数值
场景:用户历史 = [护肤水, 精华液, 面霜],下一个物品 = 眼霜 X。
稠密 Loss 的作用:让 Encoder 输出 $\hat{\mathbf{E}}$ 与"眼霜 X"的文本 embedding(从"修复眼周细纹、紧致提拉"等属性编码)相似。这样 Encoder 学会了"给定护肤序列,预测下一个物品的文本语义空间位置"。
生成 Loss 的作用:让 Decoder 学会从序列 Embedding 生成眼霜 X 的 Semantic ID(如 (7, 2, 15, 3))。这让 Decoder 能做 Beam Search 粗召。
推理时的分工:Decoder 先用 Beam Search 从"语义空间"召回 K 个候选(包含了粗粒度相关的物品),Encoder 再做细粒度稠密排序,用文本语义相似度精选 Top-K。两步互补:生成式缩小搜索空间,稠密做精排。
推理三步流程
用 Decoder 做 Beam Search,生成 $K$ 个 Semantic ID 候选,每个 ID 对应训练集中的一个物品。候选集 $\mathcal{I}_{\text{beam}} = \text{TF}([\mathbf{E}_1, \ldots, \mathbf{E}_n]; K)$。$K$ 通常远小于全量物品数 $N$(如 $K=20$ vs $N \approx 12000$),大幅压缩搜索空间。
将训练期间未见过的新物品集合 $\mathcal{C}$(即冷启动物品集)直接并入候选集:$\mathcal{I}_{\text{comb}} = \mathcal{I}_{\text{beam}} \cup \mathcal{C}$。实际系统中,新物品定期入库,$|\mathcal{C}|$ 相对较小,这一步代价可控。这是显式解决冷启动问题的关键——不依赖生成式模型"自发"生成冷启动物品,而是主动将其注入候选集。
用 Encoder 的输出 $\hat{\mathbf{E}}$ 与所有候选物品的文本 embedding 计算余弦相似度,取 Top-K:$\hat{\mathcal{I}} = \text{topk}(\text{sim}(\hat{\mathbf{E}}, \mathbf{e}_i^{\text{text}}),\; \forall i \in \mathcal{I}_{\text{comb}})$。这一步的计算量是 $O(K + |\mathcal{C}|)$,远小于全量稠密检索的 $O(N)$。
与 TIGER 的核心区别
| 对比维度 | TIGER | LIGER |
|---|---|---|
| 架构 | Encoder-Decoder T5(仅用 Decoder 推理) | Encoder-Decoder T5(双头输出) |
| 阶段2 文本 embedding | 丢弃 | 全程保留,融入输入和稠密 Loss |
| 训练目标 | 仅 next-token prediction(生成式 Loss) | 稠密对比 Loss + 生成式 Loss(联合训练) |
| 推理策略 | 纯 Beam Search,可选预留冷启动槽位 | Beam Search + 显式冷启动补充 + 稠密精排 |
| 冷启动处理 | 需预知冷启动比例 ε(不实用) | 自动补充冷启动集,无需预知比例 |
| 推理代价 | $O(t \cdot K)$(纯生成) | $O(t \cdot K) + O(K + |\mathcal{C}|)$(略高) |
实验设置
在 4 个数据集上评估:Amazon Beauty、Sports and Outdoors、Toys and Games(Amazon Review 2014),以及 Steam 游戏数据集。5-core 过滤,序列截取最近 20 个,leave-one-out 划分,用 Recall@10 和 NDCG@10 评估。
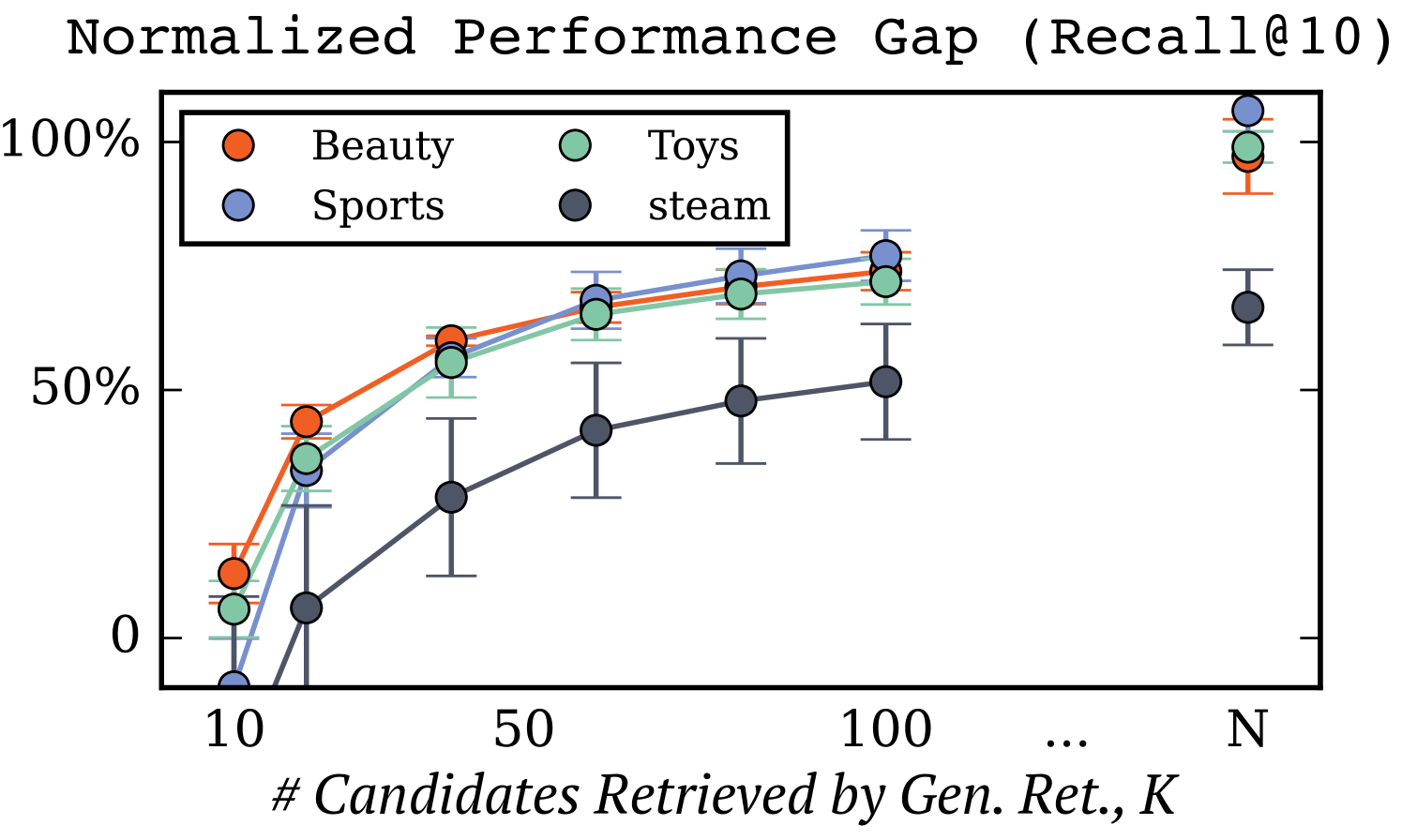
NPG(标准化性能差距)分析
定义归一化性能差距(NPG)来量化 LIGER 弥合两者差距的程度:
- $r(K)$:LIGER 用 $K$ 个 Beam Search 候选时的 Recall@10
- $r_{\text{TIGER}}$:TIGER 的 Recall@10(NPG = 0% 时的基准)
- $r_{\text{dense}}$:纯稠密检索的 Recall@10(NPG = 100% 时的上界)
- $\text{NPG}(K) = 0\%$:与 TIGER 性能相同;$= 100\%$:追上稠密检索
主要实验结果
| 方法 | 类型 | In-set Recall@10 | Cold-start Recall@10 | 备注 |
|---|---|---|---|---|
| SASRec | ID-based Dense | 低 | 很差 | 无文本先验 |
| UniSRec | Text-based Dense | 中高 | 中高 | 文本预训练 |
| RecFormer | Text-based Dense | 中高 | 中高 | LM 预训练 |
| TIGER | Generative | 中 | ≈ 0 | 冷启动失效 |
| LIGER(K=20) | Hybrid | 最高或第二 | 最高或第二 | K=20 候选 |
1. 公平比较的价值
LIGER 最大的贡献之一不是方法,而是实验设计:严格控制输入信息和模型架构,让两种范式在同一起跑线上竞争。过去很多工作在不等价条件下比较生成式和稠密检索,结论误导性很强。这种"控制变量"的思路为后续工作提供了可信的基准。
2. 冷启动是架构性问题
生成式检索的核心问题不在"生成什么",而在"生成分布覆盖范围有限"——训练集之外的物品概率天然趋零,这是自回归生成的固有局限,不能靠加更多训练数据或更好的文本 embedding 解决。
LIGER 选择了最务实的方案:绕开这个限制,而不是试图修复它。显式补充冷启动候选集是一个简单但有效的工程解法。
3. LIGER 是"混合推荐"思路的先驱
| 工作 | 与 LIGER 的关系 |
|---|---|
| TIGER(NeurIPS 2023) | LIGER 的基础,发明了 RQ-VAE SID 和生成式召回范式 |
| COBRA(Baidu 2025) | 更进一步:直接在生成式过程中融入稠密向量(BeamFusion),而非 LIGER 的"后处理"方式 |
| ETEGRec(RUC+快手 2025) | 端到端联合训练 tokenizer 和推荐模型,从根源解决两阶段解耦的次优问题 |
| OneRec(快手 2025) | 工业级直接生成,跳过稠密检索阶段,用 MoE 扩容解决精度问题 |
| GRID(Snap 2025) | 开源基准框架,系统比较 RK-Means vs RQ-VAE 等 tokenization 方案 |
4. 局限性与未解问题
- 学术集结论不代表工业结论:小规模数据集(万级物品)vs 工业级数据集(亿级物品),生成式检索的存储/计算优势在后者更为显著,精度差距也可能缩小甚至逆转
- 推理开销小幅增加:LIGER = Beam Search + 稠密精排,比纯生成式略慢,但比纯稠密($O(N)$)快很多。实际工程部署时需要仔细测量 latency
- 冷启动集的维护:需要一个实时或定时更新的"新物品集合 $\mathcal{C}$",引入了额外的系统复杂度
- K 的选择:K 越大性能越好,但代价也越高。论文用 K=20,但最优 K 因数据集和业务需求而异
5. 对工程师的启发
- 生成式检索在小规模场景不如稠密检索,但这不是"生成式检索没价值"——而是提示我们需要更好的设计(如 COBRA、OneRec 的工业级方案)
- 冷启动问题需要显式设计,不能依赖模型自发泛化——无论是 LIGER 的补充集方法,还是 ETEGRec 的端到端对齐,都是针对冷启动的主动设计
- "用生成式缩小候选空间 + 用稠密排序精排"这个 Pipeline 思路,在工业搜索/推荐中有广泛应用价值,不局限于本文的小规模实验
- Encoder-Decoder 双头训练(既生成 SID 又预测稠密向量)是 LIGER 的核心架构选择,后续 COBRA 等工作均在此基础上发展