GPSD 发现判别式推荐过拟合的根源在于稀疏嵌入训练不充分,通过先用自回归生成式 Transformer 预训练得到高质量嵌入表(采样 Softmax 解决稀疏性),再将嵌入表迁移并冻结(Sparse Freeze)进行判别式微调,彻底消除了两种过拟合现象,首次在推荐系统判别式任务上建立了从 13K 到 0.3B 参数的幂律 Scaling Law,并在 AliExpress 在线 A/B 测试中取得显著增益。
论文:Scaling Transformers for Discriminative Recommendation via Generative Pretraining
机构:Alibaba Group(AliExpress 电商推荐系统)
1.1 判别式推荐的两大顽疾
在工业级推荐系统的排序阶段,模型通常以判别式方式训练:给定用户行为序列和候选 item,预测用户会不会点击/购买(CTR/CVR 预测)。当研究者尝试把 NLP 领域的成功经验——用更大的 Transformer 模型获得更好效果——迁移到推荐场景时,遭遇了两个严重阻碍:
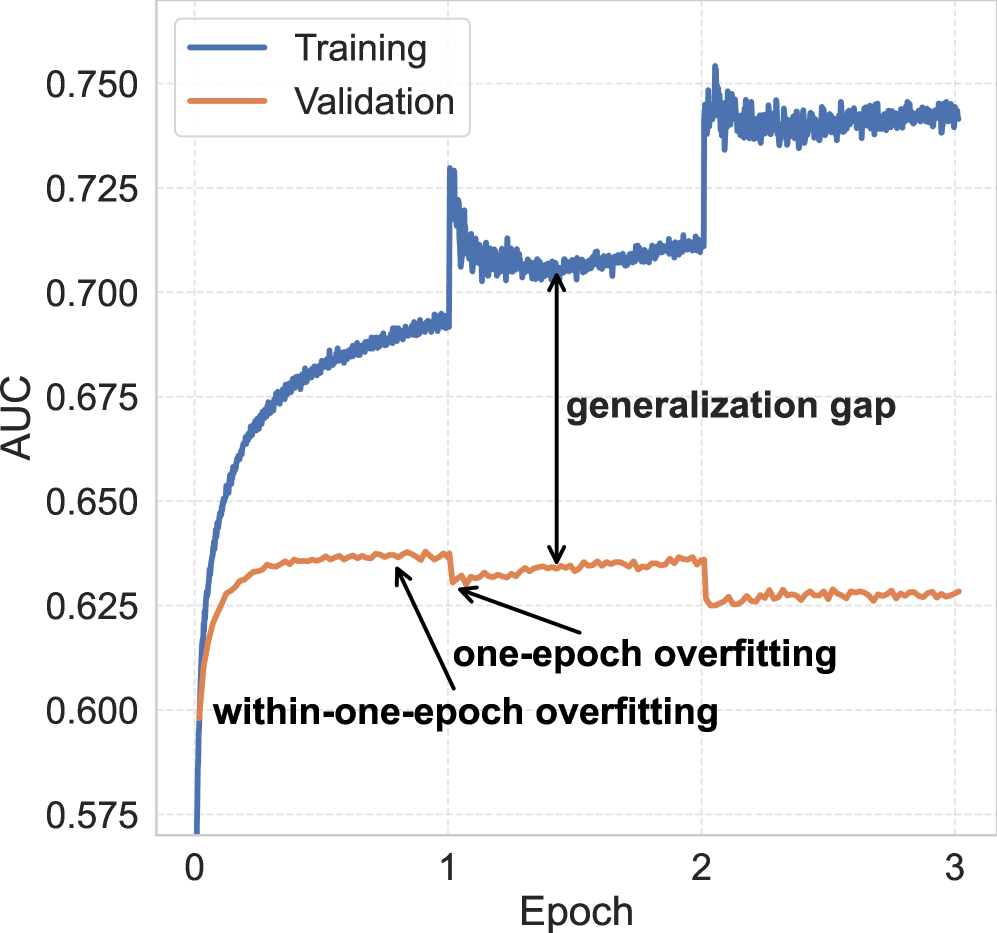
顽疾 1:严重的过拟合(Overfitting)
论文区分了两种过拟合现象:
- One-epoch overfitting:在每个 epoch 交界处,验证 AUC 会发生突然的剧烈下跌。原因是每个 epoch 结束时,模型的嵌入表已经被本 epoch 数据"重塑",对下一个 epoch 的旧数据造成分布偏移。
- Within-one-epoch overfitting:更隐蔽的过拟合——在 epoch 开始后的某个时间点,训练 AUC 还在持续上升,但验证 AUC 几乎停止增长。这说明模型在"死记硬背"训练集里的噪声,而非学习泛化规律。
顽疾 2:模型缩放无效(Scaling Doesn't Work)
在 NLP 中,模型参数量越大,效果越好(Scaling Law)。但在判别式推荐中,更大的模型反而更差——因为参数越多,过拟合越严重,大模型的泛化性能不如小模型。
这意味着工业界为了追求性能,只能不断堆 特征工程 而无法靠增大模型获益,推荐系统被困在了"小模型"时代。

1.2 关键观察:为什么生成式模型不过拟合?
论文的关键洞察来自对比:用相同 Transformer 架构训练一个生成式推荐模型(自回归地预测下一个 item),训练和验证的 loss 曲线始终保持很小的常数差距,不存在任何过拟合。而且更大的生成式模型始终更好,Scaling Law 完全成立。
为什么?论文的假设:
- 生成式训练使用采样 Softmax(Sampled Softmax),每个正样本都会随机采样大量负 item。这意味着每个 item 的嵌入向量会被频繁更新——尾部 item 和头部 item 的嵌入都有充分的训练。
- 相比之下,判别式训练只用展示给用户的 item 对作为样本,稀疏性极强——头部 item 训练充分,尾部 item 几乎没有梯度,嵌入表质量极差,导致过拟合。
解法:用生成式预训练把嵌入表训练好,然后把这套高质量嵌入冻结,只让 Transformer 的 dense 参数在判别式阶段更新。这样判别式训练就再也不需要去学习嵌入表,过拟合问题从根源上被消除。
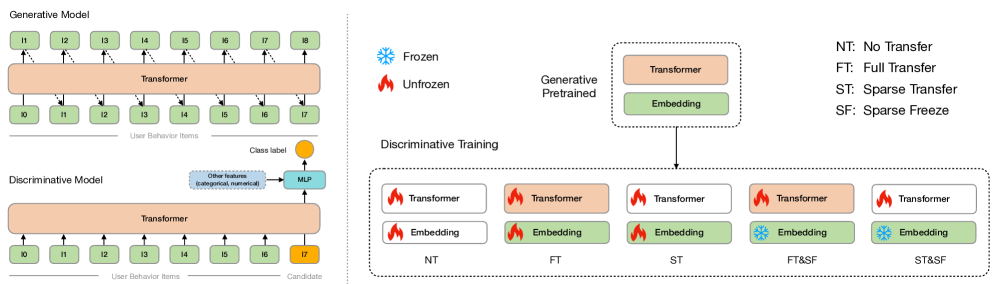
2.1 生成式预训练(Generative Pretraining)
第一阶段:用 Transformer 自回归地学习用户行为序列的生成分布。给定用户行为序列 $X = (x_1, x_2, \ldots, x_L)$,目标是最小化序列的负对数似然:
- $X = (x_1, \ldots, x_L)$:用户的历史行为 item 序列,按时间先后排列
- $\hat{p}(x_l \mid x_1, \ldots, x_{l-1})$:Transformer 预测在看了前 $l-1$ 个 item 后,下一个 item 是 $x_l$ 的概率
- 采用采样 Softmax而非 Full Softmax:从全量 item 中随机采样 $|N|$ 个负 item,大幅降低计算开销
采样 Softmax 的形式:
- $f(x;\, \text{context})$:Transformer 对 item $x$ 给出的 logit 分值(context 为前序序列)
- $N$:从全量 item 中随机采样的负 item 集合(大小通常为几百到几千)
- 采样 Softmax 保证了每个 item(包括尾部 item)都有机会作为负样本被训练,解决稀疏性问题
- Transformer 结构:采用 Pre-Norm、RMSNorm、RoPE、SwiGLU 等现代 LLM 技术
假设系统中有 400 万个 item,其中 10% 是头部 item(有大量用户行为),90% 是尾部 item(几乎没有行为)。
判别式训练(CTR):只用有展示记录的 item 对训练。尾部 item 几乎不出现在训练集中 → 嵌入向量几乎不更新 → 质量差 → 模型无法通过嵌入表学到泛化的 item 表示 → 过拟合。
生成式预训练(GPSD):每条训练样本都会随机采样 1000 个负 item。即使某个尾部 item $x$ 只有 10 次正向行为,它作为负样本出现的频率是 $\frac{1000}{4M} \times$ 训练总步数,远比正样本出现次数多。所有 item 的嵌入都能充分更新,嵌入表质量大幅提升。
2.2 判别式微调(Discriminative Training)
第二阶段:基于预训练的 Transformer,进行 CTR/CVR 等判别式任务的微调。
模型架构调整:
- 将候选 item 与用户历史序列拼接后输入 Transformer(与生成式阶段的区别:不再是纯自回归,需要候选 item 的信息)
- 在历史 item 和候选 item 的嵌入上分别加 Segment Embedding,帮助模型区分两类输入
- Transformer 最后一层的输出拼接其他类别特征和数值特征,输入 MLP head 预测 CTR 概率
- 默认使用单向 Transformer(causal mask),与在线 serving 时的 KV-cache 优化兼容
2.3 五种迁移策略:关键消融实验
如何把预训练的权重迁移到判别式模型?论文提出并对比了五种策略:
| 策略 | 稀疏参数(嵌入表) | Dense 参数(Transformer 权重) | 效果 |
|---|---|---|---|
| NT(No Transfer) | 随机初始化 | 随机初始化 | 基线,严重过拟合 |
| FT(Full Transfer) | 从预训练迁移 | 从预训练迁移 | 轻微改善,仍过拟合 |
| ST(Sparse Transfer) | 从预训练迁移 | 随机初始化 | 轻微改善,仍过拟合 |
| FT&SF(Full Transfer + Sparse Freeze) | 从预训练迁移并冻结 | 从预训练迁移 | 显著改善,适合小数据集和大模型 |
| ST&SF(Sparse Transfer + Sparse Freeze) | 从预训练迁移并冻结 | 随机初始化 | 显著改善,支持跨架构迁移,更灵活 |
2.4 稀疏参数冻结的本质分析
为什么冻结稀疏参数有效?论文通过训练曲线给出了直观解释:
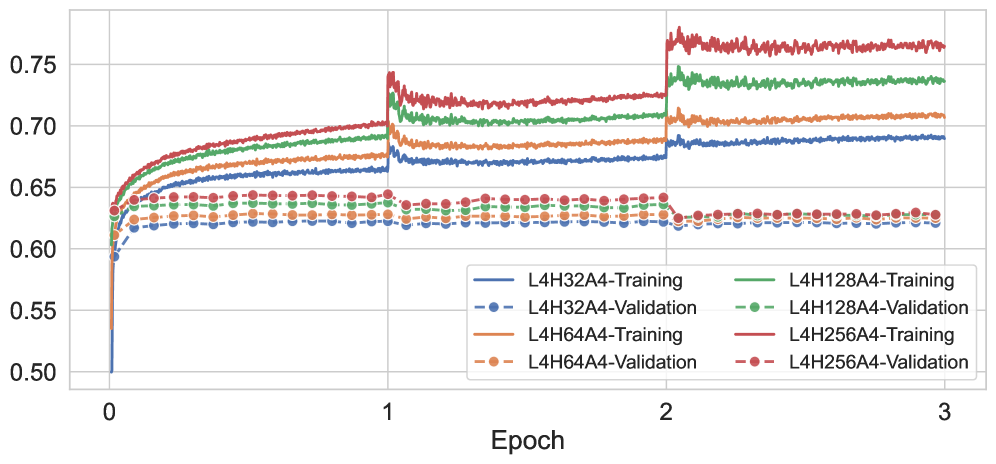

机制解释:
- 生成式预训练阶段:嵌入表获得了充分、高质量的训练(所有 item 都被充分更新)
- 判别式微调阶段:冻结嵌入表,模型只需要学习如何用这套高质量嵌入计算用户-item 相关性(Transformer dense 参数),而不需要再去纠正嵌入表的噪声
- 结果:训练信号全部用于优化 dense 参数,这部分参数的优化不存在稀疏性问题,因此不过拟合
类比:一个翻译模型,先用大量无标注文本学好"词向量"(生成式预训练),再只用少量标注数据训练"翻译策略"(判别式微调),同时把词向量冻结不变。
如果不冻结词向量:少量标注数据会把好不容易学好的词向量"带偏",导致泛化性差。
如果冻结词向量:翻译策略的训练完全不受词向量质量的拖累,少量标注数据足够训练好翻译策略,最终效果远优于不冻结。
GPSD 的 SF 策略完全遵循同样的逻辑:嵌入表是"词向量",Transformer dense 参数是"翻译策略"。
3.1 工业数据集消融(内部 CTR/CVR/CART 数据集)
| 策略 | CTR | CVR | CART | 备注 |
|---|---|---|---|---|
| NT(基线,无预训练) | — | — | — | 基线 |
| FT | 轻微+ | 轻微+ | 轻微+ | 改善不稳定 |
| ST | 轻微+ | 轻微+ | 轻微+ | 改善不稳定 |
| FT&SF | 显著+ | 显著+ | 显著+ | 小数据/大模型最优 |
| ST&SF | 显著+ | 显著+ | 显著+ | 支持跨架构,生产推荐 |
3.2 Scaling Law 验证:13K → 0.3B 参数

- Dense 参数从 13K 到 327M(约 25,000 倍),AUC 持续单调提升
- Sparse 参数从 125M 到 4B(32 倍扩展)
- 拟合的 AUC 经验上界:约 0.7097(AUC 绝对值,即理论天花板)
- 拟合的 Loss 经验下界:约 0.3695
3.3 跨架构迁移(Cross-Architecture Transfer)

ST&SF 策略的最大工程价值:嵌入表的迁移是跨架构的。即使排序模型用的不是 Transformer(如 Wukong、HSTU),只要嵌入维度相同,就可以把生成式 Transformer 预训练的嵌入表直接搬过来用,同样能获得显著提升和 Scaling Law 效果。这使得 GPSD 成为一个与架构解耦的通用框架。
3.4 公开数据集验证(Taobao、Amazon Electronics/Foods)
| 基线模型 | 原始 AUC | + ST&SF 后 AUC | 相对提升 |
|---|---|---|---|
| DeepFM | 基准 | +2.36%~5.12% | 各数据集范围 |
| DIN | 基准 | +2.67%~8.01% | |
| DIEN | 基准 | +3.15%~9.43% | |
| Transformer(NT) | 弱于所有基线 | +最大 10.03%,超过所有基线 | 从最差到最优 |
3.5 在线 A/B 测试(AliExpress 电商)
- 在 CTR、CVR、GMV 等核心指标上均有显著正向提升(具体数值论文中以表格形式呈现)
- 模型规模:使用了 3 层 Transformer(L3H160A4),参数量相对较小但已能覆盖主要收益
- 增量训练集成:生产环境采用增量 GPSD(Incremental-GPSD),每天增量训练生成式模型,每天将新的嵌入表迁移给排序模型,保持 SID 与流量分布的同步
GPSD 发现判别式推荐过拟合的根源在于稀疏嵌入训练不充分,通过先用自回归生成式 Transformer 预训练得到高质量嵌入表(采样 Softmax 解决稀疏性),再将嵌入表迁移并冻结(Sparse Freeze)进行判别式微调,彻底消除了两种过拟合现象,首次在推荐系统判别式任务上建立了从 13K 到 0.3B 参数的幂律 Scaling Law,并在 AliExpress 在线 A/B 测试中取得显著增益。
✅ 主要亮点
- 严格区分了两种过拟合(one-epoch / within-one-epoch)并分别分析了成因
- ST&SF 策略架构无关,可作为 plug-in 应用到任意排序模型(DeepFM、DIN、HSTU、Wukong)
- 首次在推荐判别式任务建立幂律 Scaling Law,指明了推荐系统的规模化路径
- 增量 GPSD 框架解决了生产环境嵌入表实时同步问题,具有高工程价值
- 代码完整开源,可直接复现
⚠️ 局限与注意
- 生成式预训练需要独立维护,增加了系统复杂度和资源开销
- 嵌入表冻结意味着排序模型无法通过在线训练"纠正"嵌入质量——生成式预训练的质量上限直接决定了最终效果上限
- 实验中序列长度相对较短($L_{\max} = 100$),超长序列(万级别)的效果有待验证
- FT&SF 和 ST&SF 在不同场景下各有优势,需要根据数据集大小和模型规模选择